Оценка уровней значимости коэффициентов регрессионного уравнения. Оценка статистической значимости уравнения регрессии и его параметров
Оценка значимости параметров уравнения регрессии
Оценка значимости параметров уравнения линейной регрессии производится с помощью критерия Стьюдента:
если t расч. > t кр, то принимается основная гипотеза (H o ), свидетельствующая о статистической значимости параметров регрессии;
если t расч. < t кр, то принимается альтернативная гипотеза (H 1 ), свидетельствующая о статистической незначимости параметров регрессии.
где m a , m b – стандартные ошибки параметров a и b:
 (2.19)
(2.19)
 (2.20)
(2.20)
Критическое (табличное) значение критерия находится с помощью статистических таблиц распределения Стьюдента (приложение Б) или по таблицам Excel (раздел мастера функций «Статистические»):
t кр = СТЬЮДРАСПОБР(α=1-P; k=n-2 ), (2.21)
где k=n-2 также представляет собой число степенейсвободы.
Оценка статистической значимости может быть применена и к линейному коэффициенту корреляции
где m r – стандартная ошибка определения значений коэффициента корреляции r yx
 (2.23)
(2.23)
Ниже представлены варианты заданий для практических и лабораторных работ по тематике второго раздела.
Вопросы для самопроверки по 2 разделу
1. Укажите основные составляющие эконометрической модели и их сущность.
2. Основное содержание этапов эконометрического исследования.
3. Сущность подходов по определению параметров линейной регрессии.
4. Сущность и особенность применения метода наименьших квадратов при определении параметров уравнения регрессии.
5. Какие показатели используются для оценки тесноты взаимосвязи исследуемых факторов?
6. Сущность линейного коэффициента корреляции.
7. Сущность коэффициента детерминации.
8. Сущность и основные особенности процедур оценки адекватности (статистической значимости) регрессионных моделей.
9. Оценка адекватности линейных регрессионных моделей по коэффициенту аппроксимации.
10. Сущность подхода оценки адекватности регрессионных моделей по критерию Фишера. Определение эмпирических и критических значений критерия.
11. Сущность понятия «дисперсионный анализ» применительно к эконометрическим исследованиям.
12. Сущность и основные особенности процедуры оценки значимости параметров линейного уравнения регрессии.
13. Особенности применения распределения Стьюдента при оценке значимости параметров линейного уравнения регрессии.
14. В чем состоит задача прогноза единичных значений исследуемого социально-экономического явления?
1. Построить поле корреляции и сформулировать предположение о форме уравнения взаимосвязи исследуемых факторов;
2. Записать основные уравнения метода наименьших квадратов, произвести необходимые преобразования, составить таблицу для промежуточных расчетов и определить параметры линейного уравнения регрессии;
3. Осуществить проверку правильности проведенных вычислений с помощью стандартных процедур и функций электронных таблиц Excel.
4. Провести анализ результатов, сформулировать выводы и рекомендации.
1. Расчет значения линейного коэффициента корреляции;
2. Построение таблицы дисперсионного анализа;
3. Оценка коэффициента детерминации;
4. Осуществить проверку правильности проведенных вычислений с помощью стандартных процедур и функций электронных таблиц Excel.
5. Провести анализ результатов, сформулировать выводы и рекомендации.
4. Провести общую оценку адекватности выбранного уравнения регрессии;
1. Оценка адекватности уравнения по значениям коэффициента аппроксимации;
2. Оценка адекватности уравнения по значениям коэффициента детерминации;
3. Оценка адекватности уравнения по критерию Фишера;
4. Провести общую оценку адекватности параметров уравнения регрессии;
5. Осуществить проверку правильности проведенных вычислений с помощью стандартных процедур и функций электронных таблиц Excel.
6. Провести анализ результатов, сформулировать выводы и рекомендации.
1. Использование стандартных процедур мастера функций электронных таблиц Excel (из разделов «Математические» и «Статистические»);
2. Подготовка данных и особенности применения функции «ЛИНЕЙН»;
3. Подготовка данных и особенности применения функции «ПРЕДСКАЗ».
1. Использование стандартных процедур пакета анализа данных электронных таблиц Excel;
2. Подготовка данных и особенности применения процедуры «РЕГРЕССИЯ»;
3. Интерпретация и обобщение данных таблицы регрессионного анализа;
4. Интерпретация и обобщение данных таблицы дисперсионного анализа;
5. Интерпретация и обобщение данных таблицы оценки значимости параметров уравнения регрессии;
При выполнении лабораторной работы по данным одного из вариантов необходимо выполнить следующие частные задания:
1. Осуществить выбор формы уравнения взаимосвязи исследуемых факторов;
2. Определить параметры уравнения регрессии;
3. Провести оценку тесноты взаимосвязи исследуемых факторов;
4. Провести оценку адекватности выбранного уравнения регрессии;
5. Провести оценку статистической значимости параметров уравнения регрессии.
6. Осуществить проверку правильности проведенных вычислений с помощью стандартных процедур и функций электронных таблиц Excel.
7. Провести анализ результатов, сформулировать выводы и рекомендации.
Задания для практических и лабораторных работ по теме «Парная линейная регрессия и корреляция в эконометрических исследованиях».
| Вариант 1 | Вариант 2 | Вариант 3 | Вариант 4 | Вариант 5 | |||||
| x | y | x | y | x | y | x | y | x | y |
| Вариант 6 | Вариант 7 | Вариант 8 | Вариант 9 | Вариант 10 | |||||
| x | y | x | y | x | y | x | y | x | y |
После того, как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров.
Проверить значимость уравнения регрессии - значит установить, соответствует ли математическая модель, выражающая зависимость между переменными, экспериментальным данным и достаточно ли включённых в уравнение объясняющих переменных (одной или нескольких) для описания зависимой переменной.
Проверка значимости производится на основе дисперсионного анализа.
Согласно идее дисперсионного анализа, общая сумма квадратов отклонений (СКО) y от среднего значения раскладывается на две части - объясненную и необъясненную:
или, соответственно:
Здесь возможны два крайних случая: когда общая СКО в точности равна остаточной и когда общая СКО равна факторной.
В первом случае фактор х не оказывает влияния на результат, вся дисперсия y обусловлена воздействием прочих факторов, линия регрессии параллельна оси Ох и уравнение должно иметь вид.
Во втором случае прочие факторы не влияют на результат, y связан с x функционально, и остаточная СКО равна нулю.
Однако на практике в правой части присутствуют оба слагаемых. Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации y приходится на объясненную вариацию. Если объясненная СКО будет больше остаточной СКО, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на результат y. Это равносильно тому, что коэффициент детерминации будет приближаться к единице.
Число степеней свободы (df-degrees of freedom) - это число независимо варьируемых значений признака.
Для общей СКО требуется (n-1) независимых отклонений,
Факторная СКО имеет одну степень свободы, и
Таким образом, можем записать:
Из этого баланса определяем, что = n-2.

Разделив каждую СКО на свое число степеней свободы, получим средний квадрат отклонений, или дисперсию на одну степень свободы: - общая дисперсия, - факторная, - остаточная.
Анализ статистической значимости коэффициентов линейной регрессии
Хотя теоретические значения коэффициентов уравнения линейной зависимости предполагаются постоянными величинами, оценки а и b этих коэффициентов, получаемые в ходе построения уравнения по данным случайной выборки, являются случайными величинами. Если ошибки регрессии имеют нормальное распределение, то оценки коэффициентов также распределены нормально и могут характеризоваться своими средними значениями и дисперсией. Поэтому анализ коэффициентов начинается с расчёта этих характеристик.
Дисперсии коэффициентов рассчитываются по формулам:
Дисперсия коэффициента регрессии:

где - остаточная дисперсия на одну степень свободы.
Дисперсия параметра:

Отсюда стандартная ошибка коэффициента регрессии определяется по формуле:

Стандартная ошибка параметра определяется по формуле:

Они служат для проверки нулевых гипотез о том, что истинное значение коэффициента регрессии b или свободного члена a равно нулю: .
Альтернативная гипотеза имеет вид: .
t - статистики имеют t - распределение Стьюдента с степенями свободы. По таблицам распределения Стьюдента при определённом уровне значимости б и степенях свободы находят критическое значение.
Если, то нулевая гипотеза должна быть отклонена, коэффициенты считаются статистически значимыми.
Если, то нулевая гипотеза не может быть отклонена. (В случае, если коэффициент b статистически незначим, уравнение должно иметь вид, и это означает, что связь между признаками отсутствует. В случае, если коэффициент а статистически незначим, рекомендуется оценить новое уравнение в виде).
Интервальные оценки коэффициентов линейного уравнения регрессии:
Доверительный интервал для а: .
Доверительный интервал для b:
Это означает, что с заданной надёжностью (где - уровень значимости) истинные значения а, b находятся в указанных интервалах.
Коэффициент регрессии имеет четкую экономическую интерпретацию, поэтому доверительные границы интервала не должны содержать противоречивых результатов, например, Они не должны включать нуль.
Анализ статистической значимости уравнения в целом.
Распределение Фишера в регрессионном анализе
Оценка значимости уравнения регрессии в целом дается с помощью F- критерия Фишера. При этом выдвигается нулевая гипотеза о том, что все коэффициенты регрессии, за исключением свободного члена а, равны нулю и, следовательно, фактор х не оказывает влияния на результат y (или).
Величина F - критерия связана с коэффициентом детерминации. В случае множественной регрессии:
где m - число независимых переменных.
В случае парной регрессии формула F - статистики принимает вид:
При нахождении табличного значения F- критерия задается уровень значимости (обычно 0,05 или 0,01) и две степени свободы: - в случае множественной регрессии, - для парной регрессии.
Если, то отклоняется и делается вывод о существенности статистической связи между y и x.
Если, то вероятность уравнение регрессии считается статистически незначимым, не отклоняется.
Замечание. В парной линейной регрессии. Кроме того, поэтому. Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
Распределение Фишера может быть использовано не только для проверки гипотезы об одновременном равенстве нулю всех коэффициентов линейной регрессии, но и гипотезы о равенстве нулю части этих коэффициентов. Это важно при развитии линейной регрессионной модели, так как позволяет оценить обоснованность исключения отдельных переменных или их групп из числа объясняющих переменных, или же, наоборот, включения их в это число.
Пусть, например, вначале была оценена множественная линейная регрессия по п наблюдениям с т объясняющими переменными, и коэффициент детерминации равен, затем последние k переменных исключены из числа объясняющих, и по тем же данным оценено уравнение, для которого коэффициент детерминации равен (, т.к. каждая дополнительная переменная объясняет часть, пусть небольшую, вариации зависимой переменной).
Для того, чтобы проверить гипотезу об одновременном равенстве нулю всех коэффициентов при исключённых переменных, рассчитывается величина
имеющая распределение Фишера с степенями свободы.
По таблицам распределения Фишера, при заданном уровне значимости, находят. И если, то нулевая гипотеза отвергается. В таком случае исключать все k переменных из уравнения некорректно.
Аналогичные рассуждения могут быть проведены и по поводу обоснованности включения в уравнение регрессии одной или нескольких k новых объясняющих переменных.
В этом случае рассчитывается F - статистика
имеющая распределение. И если она превышает критический уровень, то включение новых переменных объясняет существенную часть необъяснённой ранее дисперсии зависимой переменной (т.е. включение новых объясняющих переменных оправдано).
Замечания. 1. Включать новые переменные целесообразно по одной.
2. Для расчёта F - статистики при рассмотрении вопроса о включении объясняющих переменных в уравнение желательно рассматривать коэффициент детерминации с поправкой на число степеней свободы.
F - статистика Фишера используется также для проверки гипотезы о совпадении уравнений регрессии для отдельных групп наблюдений.
Пусть имеются 2 выборки, содержащие, соответственно, наблюдений. Для каждой из этих выборок оценено уравнение регрессии вида. Пусть СКО от линии регрессии (т.е.) равны для них, соответственно, .
Проверяется нулевая гипотеза: о том, что все соответствующие коэффициенты этих уравнений равны друг другу, т.е. уравнение регрессии для этих выборок одно и то же.
Пусть оценено уравнение регрессии того же вида сразу для всех наблюдений, и СКО.
Тогда рассчитывается F - статистика по формуле:
Она имеет распределение Фишера с степенями свободы. F - статистика будет близкой к нулю, если уравнение для обеих выборок одинаково, т.к. в этом случае. Т.е. если, то нулевая гипотеза принимается.
Если же, то нулевая гипотеза отвергается, и единое уравнение регрессии построить нельзя.
Проверить значимость параметров уравнения регрессии можно, используя t-статистику .
Задание:
По группе предприятий, выпускающих один и тот же вид продукции, рассматриваются функции издержек:
y = α + βx;
y = α x β ;
y = α β x ;
y = α + β / x;
где y – затраты на производство, тыс. д. е.
x – выпуск продукции, тыс. ед.
Требуется:
1. Построить уравнения парной регрессии y от x:
- линейное;
- степенное;
- показательное;
- равносторонней гиперболы.
3. Оценить статистическую значимость уравнения регрессии в целом.
4. Оценить статистическую значимость параметров регрессии и корреляции.
5. Выполнить прогноз затрат на производство при прогнозном выпуске продукции, составляющем 195 % от среднего уровня.
6. Оценить точность прогноза, рассчитать ошибку прогноза и его доверительный интервал.
7. Оценить модель через среднюю ошибку аппроксимации.
Решение :
1. Уравнение имеет вид y = α + βx
1. Параметры уравнения регрессии.
Средние значения
Дисперсия
Среднеквадратическое отклонение
Коэффициент корреляции
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.94 2 = 0.89, т.е. в 88.9774 % случаев изменения х приводят к изменению y. Другими словами - точность подбора уравнения регрессии - высокая
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp) 2 | (y-y(x)) 2 | (x-x p) 2 |
| 78 | 133 | 6084 | 17689 | 10374 | 142.16 | 115.98 | 83.83 | 1 |
| 82 | 148 | 6724 | 21904 | 12136 | 148.61 | 17.9 | 0.37 | 9 |
| 87 | 134 | 7569 | 17956 | 11658 | 156.68 | 95.44 | 514.26 | 64 |
| 79 | 154 | 6241 | 23716 | 12166 | 143.77 | 104.67 | 104.67 | 0 |
| 89 | 162 | 7921 | 26244 | 14418 | 159.9 | 332.36 | 4.39 | 100 |
| 106 | 195 | 11236 | 38025 | 20670 | 187.33 | 2624.59 | 58.76 | 729 |
| 67 | 139 | 4489 | 19321 | 9313 | 124.41 | 22.75 | 212.95 | 144 |
| 88 | 158 | 7744 | 24964 | 13904 | 158.29 | 202.51 | 0.08 | 81 |
| 73 | 152 | 5329 | 23104 | 11096 | 134.09 | 67.75 | 320.84 | 36 |
| 87 | 162 | 7569 | 26244 | 14094 | 156.68 | 332.36 | 28.33 | 64 |
| 76 | 159 | 5776 | 25281 | 12084 | 138.93 | 231.98 | 402.86 | 9 |
| 115 | 173 | 13225 | 29929 | 19895 | 201.86 | 854.44 | 832.66 | 1296 |
| 0 | 0 | 0 | 16.3 | 20669.59 | 265.73 | 6241 | ||
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 25672.31 | 2829.74 | 8774 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(1) = 4.01*1 + 99.18 = 103.19
y(2) = 4.01*2 + 99.18 = 107.2
... ... ...
2. Оценка параметров уравнения регрессии
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
T табл (n-m-1;α/2) = (11;0.05/2) = 1.796
Поскольку Tнабл > Tтабл, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически - значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.1712
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 1
(-20.41;56.24)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается
Статистическая значимость коэффициента регрессии b не подтверждается
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(a - t S a ; a + t S a)
(1.306;1.921)
(b - t b S b ; b + t b S b)
(-9.2733;41.876)
где t = 1.796
2) F-статистики
Fkp = 4.84
Поскольку F > Fkp, то коэффициент детерминации статистически значим
После того как уравнение регрессии построено и с помощью коэффициента детерминации оценена его точность, остается открытым вопрос за счет чего достигнута эта точность и соответственно можно ли этому уравнению доверять. Дело в том, что уравнение регрессии строилось не по генеральной совокупности, которая неизвестна, а по выборке из нее. Точки из генеральной совокупности попадают в выборку случайным образом, по этому в соответствии с теорией вероятности среди прочих случаев возможен вариант, когда выборка из “широкой” генеральной совокупности окажется “узкой” (рис. 15).
Рис. 15. Возможный вариант попадания точек в выборку из генеральной совокупности.
В этом случае:
а) уравнение регрессии, построенное по выборке, может значительно отличаться от уравнения регрессии для генеральной совокупности, что приведет к ошибкам прогноза;
б) коэффициент детерминации и другие характеристики точности окажутся неоправданно высокими и будут вводить в заблуждение о прогнозных качествах уравнения.
В предельном случае не исключен вариант, когда из генеральной совокупности представляющей собой облако с главной осью параллельной горизонтальной оси (отсутствует связь между переменными) за счет случайного отбора будет получена выборка, главная ось которой окажется наклоненной к оси. Таким образом, попытки прогнозировать очередные значения генеральной совокупности опираясь на данные выборки из нее чреваты не только ошибками в оценке силы и направления связи между зависимой и независимой переменными, но и опасностью найти связь между переменными там, где на самом деле ее нет.
В условиях отсутствия информации обо всех точках генеральной совокупности единственный способ уменьшить ошибки в первом случае заключается в использовании при оценке коэффициентов уравнения регрессии метода, обеспечивающего их несмещенность и эффективность. А вероятность наступления второго случая может быть значительно снижена благодаря тому, что априори известно одно свойство генеральной совокупности с двумя независимыми друг от друга переменными – в ней отсутствует именно эта связь. Достигается это снижение за счет проверки статистической значимости полученного уравнения регрессии.
Один из наиболее часто используемых вариантов проверки заключается в следующем. Для полученного уравнения регрессии определяется -статистика - характеристика точности уравнения регрессии, представляющая собой отношение той части дисперсии зависимой переменной которая объяснена уравнением регрессии к необъясненной (остаточной) части дисперсии. Уравнение для определения -статистики в случае многомерной регрессии имеет вид:

где: - объясненная дисперсия - часть дисперсии зависимой переменной Y которая объяснена уравнением регрессии;
Остаточная дисперсия - часть дисперсии зависимой переменной Y которая не объяснена уравнением регрессии, ее наличие является следствием действия случайной составляющей;
Число точек в выборке;
Число переменных в уравнении регрессии.
Как видно из приведенной формулы, дисперсии определяются как частное от деления соответствующей суммы квадратов на число степеней свободы. Число степеней свободы это минимально необходимое число значений зависимой переменной, которых достаточно для получения искомой характеристики выборки и которые могут свободно варьироваться с учетом того, что для этой выборки известны все другие величины, используемые для расчета искомой характеристики.
Для получения остаточной дисперсии необходимы коэффициенты уравнения регрессии. В случае парной линейной регрессии коэффициентов два, по этому в соответствии с формулой (принимая ) число степеней свободы равно . Имеется в виду, что для определения остаточной дисперсии достаточно знать коэффициенты уравнения регрессии и только значений зависимой переменной из выборки. Оставшиеся два значения могут быть вычислены на основании этих данных, а значит, не являются свободно варьируемыми.
Для вычисления объясненной дисперсии значений зависимой переменной вообще не требуются, так как ее можно вычислить, зная коэффициенты регрессии при независимых переменных и дисперсию независимой переменной. Для того чтобы убедиться в этом, достаточно вспомнить приводившееся ранее выражение ![]() . По этому число степеней свободы для остаточной дисперсии равно числу независимых переменных в уравнении регрессии (для парной линейной регрессии ).
. По этому число степеней свободы для остаточной дисперсии равно числу независимых переменных в уравнении регрессии (для парной линейной регрессии ).
В результате -критерий для уравнения парной линейной регрессии определяется по формуле:
 .
.
В теории вероятности доказано, что -критерий уравнения регрессии, полученного для выборки из генеральной совокупности у которой отсутствует связь между зависимой и независимой переменной имеет распределение Фишера, достаточно хорошо изученное. Благодаря этому для любого значения -критерия можно рассчитать вероятность его появления и наоборот, определить то значение -критерия которое он не сможет превысить с заданной вероятностью.
Для осуществления статистической проверки значимости уравнения регрессии формулируется нулевая гипотеза об отсутствии связи между переменными (все коэффициенты при переменных равны нулю) и выбирается уровень значимости .
Уровень значимости – это допустимая вероятность совершить ошибку первого рода – отвергнуть в результате проверки верную нулевую гипотезу. В рассматриваемом случае совершить ошибку первого рода означает признать по выборке наличие связи между переменными в генеральной совокупности, когда на самом деле ее там нет.
Обычно уровень значимости принимается равным 5% или 1%. Чем выше уровень значимости (чем меньше ), тем выше уровень надежности теста, равный , т.е. тем больше шанс избежать ошибки признания по выборке наличия связи у генеральной совокупности на самом деле несвязанных между собой переменных. Но с ростом уровня значимости возрастает опасность совершения ошибки второго рода – отвергнуть верную нулевую гипотезу, т.е. не заметить по выборке имеющуюся на самом деле связь переменных в генеральной совокупности. По этому, в зависимости от того, какая ошибка имеет большие негативные последствия, выбирают тот или иной уровень значимости.
Для выбранного уровня значимости по распределению Фишера определяется табличное значение вероятность превышения, которого в выборке мощностью , полученной из генеральной совокупности без связи между переменными, не превышает уровня значимости. сравнивается с фактическим значением критерия для регрессионного уравнения .
Если выполняется условие , то ошибочное обнаружение связи со значением -критерия равным или большим по выборке из генеральной совокупности с несвязанными между собой переменными будет происходить с вероятностью меньшей чем уровень значимости. В соответствии с правилом “очень редких событий не бывает”, приходим к выводу, что установленная по выборке связь между переменными имеется и в генеральной совокупности, из которой она получена.
Если же оказывается , то уравнение регрессии статистически не значимо. Иными словами существует реальная вероятность того, что по выборке установлена не существующая в реальности связь между переменными. К уравнению, не выдержавшему проверку на статистическую значимость, относятся так же, как и к лекарству с истекшим сроком годнос-
Ти – такие лекарства не обязательно испорчены, но раз нет уверенности в их качестве, то их предпочитают не использовать. Это правило не уберегает от всех ошибок, но позволяет избежать наиболее грубых, что тоже достаточно важно.
Второй вариант проверки, более удобный в случае использования электронных таблиц, это сопоставление вероятности появления полученного значения -критерия с уровнем значимости. Если эта вероятность оказывается ниже уровня значимости , значит уравнение статистически значимо, в противном случае нет.
После того как выполнена проверка статистической значимости регрессионного уравнения в целом полезно, особенно для многомерных зависимостей осуществить проверку на статистическую значимость полученных коэффициентов регрессии. Идеология проверки такая же как и при проверке уравнения в целом но в качестве критерия используется -критерий Стьюдента, определяемый по формулам:
 и
и 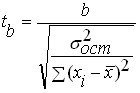
где: , - значения критерия Стьюдента для коэффициентов и соответственно;
 - остаточная дисперсия уравнения регрессии;
- остаточная дисперсия уравнения регрессии;
Число точек в выборке;
Число переменных в выборке, для парной линейной регрессии .
Полученные фактические значения критерия Стьюдента сравниваются с табличными значениями ![]() , полученными из распределения Стьюдента. Если оказывается, что , то соответствующий коэффициент статистически значим, в противном случае нет. Второй вариант проверки статистической значимости коэффициентов – определить вероятность появления критерия Стьюдента и сравнить с уровнем значимости .
, полученными из распределения Стьюдента. Если оказывается, что , то соответствующий коэффициент статистически значим, в противном случае нет. Второй вариант проверки статистической значимости коэффициентов – определить вероятность появления критерия Стьюдента и сравнить с уровнем значимости .
Для переменных, чьи коэффициенты оказались статистически не значимы, велика вероятность того, что их влияние на зависимую переменную в генеральной совокупности вообще отсутствует. По этому или необходимо увеличить число точек в выборке, тогда возможно коэффициент станет статистически значимым и заодно уточнится его значение, или в качестве независимых переменных найти другие, более тесно связанные с зависимой переменной. Точность прогнозирования при этом в обоих случаях возрастет.
В качестве экспрессного метода оценки значимости коэффициентов уравнения регрессии можно применять следующее правило – если критерий Стьюдента больше 3, то такой коэффициент, как правило, оказывается статистически значим. А вообще считается, что для получения статистически значимых уравнений регрессии необходимо, чтобы выполнялось условие .
Стандартная ошибка прогнозирования по полученному уравнению регрессии неизвестного значения при известном оценивают по формуле:

Таким образом прогноз с доверительной вероятностью 68% может быть представлен в виде:
В случае если требуется иная доверительная вероятность , то для уровня значимости необходимо найти критерий Стьюдента и доверительный интервал для прогноза с уровнем надежности будет равен ![]() .
.
Прогнозирование многомерных и нелинейных зависимостей
В случае если прогнозируемая величина зависит от нескольких независимых переменных, то в этом случае имеется многомерная регрессия вида:
где: - коэффициенты регрессии, описывающие влияние переменных на прогнозируемую величину.
Методика определения коэффициентов регрессии не отличается от парной линейной регрессии, особенно при использовании электронной таблицы, так как там применяется одна и та же функция и для парной и для многомерной линейной регрессии. При этом желательно чтобы между независимыми переменными отсутствовали взаимосвязи, т.е. изменение одной переменной не сказывалось на значениях других переменных. Но это требование не является обязательным, важно чтобы между переменными отсутствовали функциональные линейные зависимости. Описанные выше процедуры проверки статистической значимости полученного уравнения регрессии и его отдельных коэффициентов, оценка точности прогнозирования остается такой же как и для случая парной линейной регрессии. В тоже время применение многомерных регрессий вместо парной обычно позволяет при надлежащем выборе переменных существенно повысить точность описания поведения зависимой переменной, а значит и точность прогнозирования.
Кроме этого уравнения многомерной линейной регрессии позволяют описать и нелинейную зависимость прогнозируемой величины от независимых переменных. Процедура приведения нелинейного уравнения к линейному виду называется линеаризацией. В частности если эта зависимость описывается полиномом степени отличной от 1, то, осуществив замену переменных со степенями отличными от единицы на новые переменные в первой степени, получаем задачу многомерной линейной регрессии вместо нелинейной. Так, например если влияние независимой переменной описывается параболой вида
![]()
то замена позволяет преобразовать нелинейную задачу к многомерной линейной вида
![]()
Так же легко могут быть преобразованы нелинейные задачи у которых нелинейность возникает вследствие того, что прогнозируемая величина зависит от произведения независимых переменных. Для учета такого влияния необходимо ввести новую переменную равную этому произведению.
В тех случаях, когда нелинейность описывается более сложными зависимостями, линеаризация возможна за счет преобразования координат. Для этого рассчитываются значения ![]() и строятся графики зависимости исходных точек в различных комбинациях преобразованных переменных. Та комбинация преобразованных координат или преобразованных и не преобразованных координат, в которой зависимость ближе всего к прямой линии подсказывает замену переменных которая приведет к преобразованию нелинейной зависимости к линейному виду. Например, нелинейная зависимость вида
и строятся графики зависимости исходных точек в различных комбинациях преобразованных переменных. Та комбинация преобразованных координат или преобразованных и не преобразованных координат, в которой зависимость ближе всего к прямой линии подсказывает замену переменных которая приведет к преобразованию нелинейной зависимости к линейному виду. Например, нелинейная зависимость вида
превращается в линейную вида
Полученные коэффициенты регрессии для преобразованного уравнения остаются несмещенными и эффективными, но проверка статистической значимости уравнения и коэффициентов невозможна
Проверка обоснованности применения метода наименьших квадратов
Применение метода наименьших квадратов обеспечивает эффективность и несмещенность оценок коэффициентов уравнения регрессии при соблюдении следующих условий (условий Гауса-Маркова):
3. значения не зависят друг от друга
4. значения не зависят от независимых переменных
Наиболее просто можно проверить соблюдение этих условий путем построения графиков остатков в зависимости от , затем от независимой (независимых) переменных. Если точки на этих графиках расположены в коридоре расположенном симметрично оси абсцисс и в расположении точек не просматриваются закономерности, то условия Гауса-Маркова выполнены и возможности повысить точность уравнения регрессии отсутствуют. Если это не так, то существует возможность существенно повысить точность уравнения и для этого необходимо обратиться к специальной литературе.
В социально-экономических исследованиях часто приходится работать в условиях ограниченной совокупности, либо с выборочными данными. Поэтому после математических параметров уравнение регрессии необходимо оценить их и уравнение в целом на статистическую значимость, т.е. необходимо убедиться, что полученное уравнение и его параметры сформированы под влиянием неслучайных факторов.
Прежде всего, оценивается статистическая значимость уравнения в целом. Оценка, как правило, проводится с использованием F-критерия Фишера. Расчет F-критерия базируется на правиле сложения дисперсий. А именно, общего дисперсионного признака-результата = дисперсия факторная + дисперсия остаточная.
Фактическая цена
Теоретическая цена
Построив уравнение регрессии можно рассчитать теоретическое значение признака-результата, т.е. рассчитанные по уравнению регрессии с учетом его параметров.
Эти значения будут характеризовать признак-результат, сформировавшийся под влиянием факторов включенных в анализ.
Между фактическими значениями признака-результата и рассчитанными на основе уравнения регрессии всегда существуют расхождения (остатки), обусловленные влиянием прочих факторов, не включенных в анализ.
Разность между теоретическими и фактическими значениями признака-результата называется остатками. Общая вариация признака-результата:
Вариация по признаку-результату, обусловленная вариацией признаков факторов, включенных в анализ оценивается через сопоставления теоретических значений резул. признака и его средних значений. Остаточная вариация через сопоставление теоретических и фактических значений результатирующего признака. Общая дисперсия , остаточная и фактическая имеют разное число степеней свободы.
Общая , п - число единиц в изучаемой совокупности
Фактическая , п - число факторов, включенных в анализ
Остаточная
F-критерий Фишера рассчитывается как отношение к , причем рассчитаны на одну степень свободы.
Использование F-критерия Фишера в качестве оценки статистической значимости уравнения регрессии очень логично. - это результат. признака, обусловленная факторами включенными в анализ, т.е. это доля объясненной результат. признака. - это (вариация) признака результата обусловленная факторами влияние которых не учитывается, т.е. не включенными в анализ.
Т.о. F-критерий призван оценить значимое превышение над . Если несущественно ниже , а тем более, если оно превышает , следовательно, в анализ включены не те факторы, которые действительно влияют на признак-результат.
F-критерий Фишера табулирован, фактическое значение сравнивается с табличным. Если , то уравнение регрессии признается статистически значимым. Если наоборот – уравнение статистически не значимо и не может использоваться на практике, значимость уравнения в целом говорит о статистической значимости показателей корелляции.
После оценки уравнения в целом необходимо оценить статистическую значимость параметров уравнения. Эта оценка осуществляется с использованием t-статистики Стьюдента. t-статистика рассчитывается как отношение параметров уравнения (по модулю) к их стандартной средней квадратической ошибке. Если оценивается однофакторная модель, то рассчитывается 2 статистики.
Во всех компьютерных программах расчет стандартной ошибки и t-статистики для параметров проводится с расчетом самих параметров. T-статистика табулирована. Если значение , то параметр признается статистически значимым, т.е. сформированным под влиянием неслучайных факторов.
Расчет t-статистики по существу означает проверку нулевой гипотезы о незначимости параметра, т.е. равенстве его нулю. При однофакторной модели оценивается 2 гипотезы: и
Уровень значимости принятия нулевой гипотезы зависит от уровня принятой доверительной вероятности. Так если исследователь задает уровень вероятности 95%, уровень значимости принятия будет рассчитываться , следовательно, если уровень значимости ≥ 0,05, то принимается и параметры считаются статистически незначимыми. Если , то отвергается и принимается альтернатива: и .
В пакетах прикладных программ по статистике также приводится уровень значимости принятия нулевых гипотез. Оценка значимости уравнения регрессии и его параметров может дать следующие результаты:
Во-первых, уравнение в целом значимо(по F-критерию) и также статистически значимы все параметры уравнения. Это означает, что полученное уравнение может быть использовано как для принятия управленческих решений, так и для прогнозирования.
Во-вторых, по F-критерию уравнение статистически значимо, но не значим хотя бы один из параметров уравнения. Уравнение может быть использовано для принятия управленческих решений относительно анализируемых факторов, но не может быть использовано для прогнозирования.
В-третьих, уравнение статистически не значимо, либо по F- критерию уравнение значимо, но не значимы все параметры полученного уравнения. Уравнение не может быть использовано не для каких целей.
Чтобы уравнение регрессии можно было признать моделью связи между признаком-результатом и признаками-факторами необходимо чтобы в него были включены все важнейшие факторы, определяющие результат, чтобы содержательная интерпретация параметров уравнения соответствовала теоретически обоснованным связям в изучаемом явлении. Коэффициент детерминации R 2 должен быть > 0,5.
При построении множественного уравнения регрессии целесообразно осуществить оценку по так называемому скорректированному коэффициенту детерминации (R 2). Величина R 2 (как и корелляции) возрастает при увеличение числа факторов включенных в анализ. Особенно завышается значение коэф-в в условиях небольших совокупностей. С целью погасить отрицательное влияние R 2 и корелляции корректируют с учетом числа степеней свободы, т.е. числа свободно варьирующих элементов при включении определенных факторов.
Скорректированный коэф-т детерминации
п –объем совокупности/число наблюдений
k – число факторов включенных в анализ
п-1 – число степеней свободы
(1-R 2) - величина остатка/ необъясненной дисперсии результативного признака
Всегда меньше R 2 . на основе можно сравнивать оценки уравнений с разным числом анализируемых факторов.
34. Задачи изучения динамических рядов.
Ряды динамики называют временными рядами или динамическими рядами. Динамический ряд – это упорядоченная во времени последовательность показателей, характеризующих то или иное явление (объем ВВП с 90 по 98 гг). Целью изучения рядов динамики является выявление закономерности развития изучаемого явления (основной тенденции) и прогнозирование на этой основе. Из определения РД следует, что любой ряд состоит из двух элементов: время t и уровень ряда (те конкретные значения показателя, на основе которого построен ДРяд). ДРяды могут быть 1)моментными – ряды, показатели которых фиксируются на момент времени, на определенную дату, 2)интервальными – ряды, показатели которого получают за какой-то период времени (1.численность населения СПб, 2.объем ВВП за период). Разделение рядов на моментные и интервальные необходимо, поскольку это определяет специфику расчета некоторых показателей ДРядов. Суммирование уровней интервальных рядов дает содержательно интерпретируемый результат, что нельзя сказать о суммировании уровней моментных рядов, поскольку последние содержат повторный счет. Важнейшей проблемой в анализе рядов динамики является проблема сопоставимости уровней ряда. Это понятие очень разноплановое. Уровни должны быть сопоставимы по методам расчета и по территории и охвату единиц совокупности. Если ДРяд строится в стоимостных показателях, то все уровни должны быть представлены или рассчитаны в сопоставимых ценах. При построении интервальных рядов уровни должны характеризовать одинаковые отрезки времени. При построении моментных РядовД уровни должны фиксироваться на одну и ту же дату. ДРяды могут быть полными и неполными. Неполные ряды используются в официальных изданиях (1980,1985,1990,1995,1996,1997,1998,1999…). Комплексный анализ РД включает изучение следующих моментов:
1. расчет показателей изменения уровней РД
2. расчет средних показателей РД
3. выявление основной тенденции ряда, построение трендовых моделей
4. оценка автокорреляции в РД, построение авторегрессионных моделей
5. корреляция РД (изучение связей м/у ДРядами)
6. прогнозирование РД.
35. Показателей изменения уровней временных рядов .
В общем виде РядД может быть представлен:
у – уровень ДР, t – момент или период времени к которому относится уровень (показатель), n – длина ДРяда (число периодов). при изучении ряда динамики рассчитывают следующие показатели: 1. абсолютный прирост, 2. коэффициент роста (темп роста), 3. ускорение, 4. коэффициент прироста (темп прироста), 5. абсолютное значение 1 % прироста. Рассчитываемые показатели могут быть: 1. цепные – получают путем сопоставления каждого уровня ряда с непосредственно предшествующим, 2. базисные – получают путем сопоставления с уровнем, выбранным за базу сравнения (если специально не оговаривается, за базу берется 1ый уровень ряда). 1. Цепные абсолютные приросты: . Показывает на сколько больше или меньше . Цепные абсолютные приросты называют показателями скорости изменения уровней динамического ряда. Базисный абсолютный прирост : . Если уровни ряда представляют собой относительные показатели, выраженные в %-ах, то абсолютный прирост выражается в пунктах изменения. 2. коэффициент роста (темпы роста): Рассчитывается как отношение уровней ряда к непосредственно предшествующим (цепные коэффициенты роста), либо к уровню, принятому за базу сравнения (базисные коэффициенты роста): . Характеризует во сколько раз каждый уровень ряда > или < предшествующего или базисного. На основе коэффициентов роста рассчитываются темпы роста. Это коэффициенты роста, выраженные в %ах: 3. на основе абсолютных приростов рассчитывают показатель – ускорение абсолютных приростов : . Ускорение – абсолютный прирост абсолютных приростов. Оценивает как изменяются сами приросты, они стабильны или принимают ускорение (возрастают). 4. темп прироста – это отношение прироста к базе сравнения. Выражается в %-ах: ; . Темп прироста – это темп роста минус 100%. Показывает на сколько % данный уровень ряда > или < предшествующего либо базисного. 5. абсолютное значение 1% прироста. Рассчитывается как отношение абсолютного прироста к темпу прироста, т.е.: - сотая доля предыдущего уровня. Все эти показатели рассчитываются для оценки степени изменения уровней ряда. Цепные коэффициенты и темпы роста называются показателями интенсивности изменения уровней ДРядов.
2. Расчет средних показателей РД Рассчитывают средние уровни рядов, средние абсолютные приросты, средние темпы роста и средние темпы прироста. Средние показатели рассчитываются с целью обобщения информации и возможности сравнивать уровни и показатели их изменения по различным рядам. 1. средний уровень ряда а) для интервальных временных рядов рассчитывается по средней арифметической простой: , где n – число уровней во временном ряду; б) для моментных рядов средний уровень рассчитывается по специфической формуле, которая называется средней хронологической: . 2. средний абсолютный прирост рассчитывается на основе цепных абсолютных приростов по средней арифметической простой:
. 3. Средний коэффициент роста рассчитывается на основе цепных коэффициентов роста по формуле средней геометрической: . При комментарии средних показателей ДРядов необходимо указывать 2 момента: период, который характеризует анализируемый показатель и временной интервал, за который построен ДРяд. 4. Средний темп роста : . 5. средний темп прироста : .