Quantitative Analysemethoden: Schätzung von Konfidenzintervallen
Vertrauensintervalle ( Englisch Vertrauensintervalle) eine der in der Statistik verwendeten Arten von Intervallschätzungen, die für ein bestimmtes Signifikanzniveau berechnet werden. Sie ermöglichen uns die Aussage, dass der wahre Wert eines unbekannten statistischen Parameters der Bevölkerung mit einer Wahrscheinlichkeit innerhalb des erhaltenen Wertebereichs liegt, die durch das ausgewählte statistische Signifikanzniveau vorgegeben ist.
Normalverteilung
Wenn die Varianz (σ 2) der Datenpopulation bekannt ist, kann der Z-Score zur Berechnung von Konfidenzgrenzen (den Endpunkten des Konfidenzintervalls) verwendet werden. Im Vergleich zur Verwendung der t-Verteilung können Sie mit dem Z-Score nicht nur ein engeres Konfidenzintervall erstellen, sondern auch zuverlässigere Schätzungen des Erwartungswerts und der Standardabweichung (σ), da der Z-Score auf a basiert Normalverteilung.
Formel
Um die Grenzpunkte des Konfidenzintervalls zu bestimmen, wird die folgende Formel verwendet, sofern die Standardabweichung der Datenpopulation bekannt ist
| L = X - Z α/2 | σ |
| √n |
Beispiel
Gehen Sie davon aus, dass die Stichprobengröße 25 Beobachtungen beträgt, der erwartete Stichprobenwert 15 beträgt und die Populationsstandardabweichung 8 beträgt. Für ein Signifikanzniveau von α=5 % beträgt der Z-Score Z α/2 =1,96. In diesem Fall sind die Unter- und Obergrenzen des Konfidenzintervalls gleich
| L = 15 - 1,96 | 8 | = 11,864 |
| √25 |
| L = 15 + 1,96 | 8 | = 18,136 |
| √25 |
Somit können wir sagen, dass die mathematische Erwartung der Bevölkerung mit einer Wahrscheinlichkeit von 95 % in den Bereich von 11,864 bis 18,136 fallen wird.
Methoden zur Einengung des Konfidenzintervalls
Nehmen wir an, dass der Bereich für die Zwecke unserer Studie zu groß ist. Es gibt zwei Möglichkeiten, den Bereich des Konfidenzintervalls zu verringern.
- Reduzieren Sie das statistische Signifikanzniveau α.
- Erhöhen Sie die Stichprobengröße.
Wenn wir das statistische Signifikanzniveau auf α=10 % reduzieren, erhalten wir einen Z-Score von Z α/2 =1,64. In diesem Fall sind die untere und obere Grenze des Intervalls gleich
| L = 15 - 1,64 | 8 | = 12,376 |
| √25 |
| L = 15 + 1,64 | 8 | = 17,624 |
| √25 |
Und das Konfidenzintervall selbst kann in das Formular geschrieben werden
In diesem Fall können wir davon ausgehen, dass die mathematische Erwartung der Bevölkerung mit einer Wahrscheinlichkeit von 90 % in den Bereich fällt.
Wenn wir das statistische Signifikanzniveau α nicht verringern wollen, besteht die einzige Alternative darin, die Stichprobengröße zu erhöhen. Wenn wir es auf 144 Beobachtungen erhöhen, erhalten wir die folgenden Werte der Konfidenzgrenzen
| L = 15 - 1,96 | 8 | = 13,693 |
| √144 |
| L = 15 + 1,96 | 8 | = 16,307 |
| √144 |
Das Konfidenzintervall selbst hat die folgende Form
Daher ist eine Verengung des Konfidenzintervalls ohne Verringerung der statistischen Signifikanz nur durch eine Vergrößerung der Stichprobengröße möglich. Wenn eine Vergrößerung der Stichprobengröße nicht möglich ist, kann eine Verengung des Konfidenzintervalls allein durch eine Verringerung des statistischen Signifikanzniveaus erreicht werden.
Erstellen eines Konfidenzintervalls für eine andere als die Normalverteilung
Wenn die Standardabweichung der Grundgesamtheit nicht bekannt ist oder die Verteilung vom Normalwert abweicht, wird die t-Verteilung zur Konstruktion eines Konfidenzintervalls verwendet. Diese Technik ist im Vergleich zur auf dem Z-Score basierenden Technik konservativer, was sich in größeren Konfidenzintervallen widerspiegelt.
Formel
Verwenden Sie die folgenden Formeln, um die Unter- und Obergrenzen des Konfidenzintervalls basierend auf der t-Verteilung zu berechnen
| L = X – t α | σ |
| √n |
Die Student-Verteilung oder t-Verteilung hängt nur von einem Parameter ab – der Anzahl der Freiheitsgrade, die gleich der Anzahl der Einzelwerte des Attributs (der Anzahl der Beobachtungen in der Stichprobe) ist. Der Wert des Student-t-Tests für eine bestimmte Anzahl von Freiheitsgraden (n) und das statistische Signifikanzniveau α können den Referenztabellen entnommen werden.
Beispiel
Angenommen, die Stichprobengröße beträgt 25 Einzelwerte, der erwartete Stichprobenwert beträgt 50 und die Stichprobenstandardabweichung beträgt 28. Es ist erforderlich, ein Konfidenzintervall für das statistische Signifikanzniveau α = 5 % zu erstellen.
In unserem Fall beträgt die Anzahl der Freiheitsgrade 24 (25-1), daher beträgt der entsprechende Tabellenwert des Student-t-Tests für das statistische Signifikanzniveau α=5 % 2,064. Daher sind die Unter- und Obergrenzen des Konfidenzintervalls gleich
| L = 50 - 2,064 | 28 | = 38,442 |
| √25 |
| L = 50 + 2,064 | 28 | = 61,558 |
| √25 |
Und das Intervall selbst kann in der Form geschrieben werden
Somit können wir sagen, dass die mathematische Erwartung der Bevölkerung mit einer Wahrscheinlichkeit von 95 % im Bereich liegt.
Mithilfe der t-Verteilung können Sie das Konfidenzintervall verengen, indem Sie entweder die statistische Signifikanz verringern oder die Stichprobengröße erhöhen.
Wenn wir die statistische Signifikanz unter den Bedingungen unseres Beispiels von 95 % auf 90 % reduzieren, erhalten wir den entsprechenden Tabellenwert des Student-t-Tests von 1,711.
| L = 50 - 1,711 | 28 | = 40,418 |
| √25 |
| L = 50 + 1,711 | 28 | = 59,582 |
| √25 |
In diesem Fall können wir sagen, dass die mathematische Erwartung der Bevölkerung mit einer Wahrscheinlichkeit von 90 % im Bereich liegt.
Wenn wir die statistische Signifikanz nicht verringern wollen, besteht die einzige Alternative darin, die Stichprobengröße zu erhöhen. Nehmen wir an, dass es sich um 64 Einzelbeobachtungen handelt und nicht um 25 wie im Originalzustand des Beispiels. Der Tabellenwert des Student-t-Tests für 63 Freiheitsgrade (64-1) und das statistische Signifikanzniveau α=5 % beträgt 1,998.
| L = 50 - 1,998 | 28 | = 43,007 |
| √64 |
| L = 50 + 1,998 | 28 | = 56,993 |
| √64 |
Dies lässt uns sagen, dass die mathematische Erwartung der Bevölkerung mit einer Wahrscheinlichkeit von 95 % im Bereich liegt.
Große Proben
Große Stichproben sind Stichproben aus einer Datenpopulation, in der die Anzahl der Einzelbeobachtungen 100 übersteigt. Statistische Studien haben gezeigt, dass größere Stichproben tendenziell normalverteilt sind, auch wenn die Verteilung der Population nicht normal ist. Darüber hinaus führt die Verwendung eines Z-Scores und einer T-Verteilung für solche Stichproben bei der Erstellung von Konfidenzintervallen zu ungefähr denselben Ergebnissen. Daher ist es bei großen Stichproben akzeptabel, den Z-Score anstelle der T-Verteilung für die Normalverteilung zu verwenden.
Fassen wir es zusammen
In den vorherigen Unterabschnitten haben wir uns mit der Frage der Schätzung eines unbekannten Parameters befasst A eine Nummer. Dies wird als „Punktschätzung“ bezeichnet. Bei einer Reihe von Aufgaben müssen Sie nicht nur nach dem Parameter suchen A geeigneter numerischer Wert, sondern auch zur Bewertung seiner Genauigkeit und Zuverlässigkeit. Sie müssen wissen, zu welchen Fehlern das Ersetzen eines Parameters führen kann A seine Punktschätzung A Und mit welchem Maß an Sicherheit können wir erwarten, dass diese Fehler bekannte Grenzen nicht überschreiten?
Probleme dieser Art sind insbesondere bei einer kleinen Anzahl von Beobachtungen relevant, wenn die Punktschätzung erfolgt und in ist weitgehend zufällig und der ungefähre Ersatz von a durch a kann zu schwerwiegenden Fehlern führen.
Um einen Eindruck von der Genauigkeit und Zuverlässigkeit der Schätzung zu vermitteln A,
In der mathematischen Statistik werden sogenannte Konfidenzintervalle und Konfidenzwahrscheinlichkeiten verwendet.
Sei für den Parameter A unvoreingenommene, auf Erfahrung beruhende Schätzung A. Wir wollen in diesem Fall den möglichen Fehler abschätzen. Weisen wir eine ausreichend große Wahrscheinlichkeit p zu (z. B. p = 0,9, 0,95 oder 0,99), sodass ein Ereignis mit der Wahrscheinlichkeit p als praktisch zuverlässig angesehen werden kann, und finden wir einen Wert s für den
Dann der Bereich praktisch möglicher Werte des beim Austausch auftretenden Fehlers A An A, wird ± s sein; Große Absolutwertfehler treten nur mit geringer Wahrscheinlichkeit a = 1 - p auf. Schreiben wir (14.3.1) wie folgt um:
Gleichheit (14.3.2) bedeutet, dass mit Wahrscheinlichkeit p der unbekannte Wert des Parameters ist A fällt in das Intervall
Es ist notwendig, einen Umstand zu beachten. Zuvor haben wir wiederholt die Wahrscheinlichkeit betrachtet, mit der eine Zufallsvariable in ein bestimmtes nicht zufälliges Intervall fällt. Hier ist die Situation anders: die Größenordnung A ist nicht zufällig, aber das Intervall / p ist zufällig. Seine Position auf der x-Achse ist zufällig und wird durch seinen Mittelpunkt bestimmt A; Im Allgemeinen ist auch die Länge des Intervalls 2s zufällig, da der Wert von s in der Regel aus experimentellen Daten berechnet wird. Daher wäre es in diesem Fall besser, den p-Wert und nicht als Wahrscheinlichkeit, den Punkt zu „treffen“, zu interpretieren A im Intervall / p und als Wahrscheinlichkeit, dass ein zufälliges Intervall / p den Punkt abdeckt A(Abb. 14.3.1).

Reis. 14.3.1
Üblicherweise wird die Wahrscheinlichkeit p genannt Konfidenzwahrscheinlichkeit, und Intervall / p - Konfidenzintervall. Intervallgrenzen Wenn. a x =a- s und ein 2 = ein + und heißen Grenzen vertrauen.
Lassen Sie uns das Konzept eines Konfidenzintervalls anders interpretieren: Es kann als Intervall von Parameterwerten betrachtet werden A, mit experimentellen Daten kompatibel sind und diesen nicht widersprechen. Wenn wir uns tatsächlich darauf einigen, ein Ereignis mit der Wahrscheinlichkeit a = 1-p als praktisch unmöglich zu betrachten, dann sind die Werte des Parameters a für welche a - a> s müssen als widersprüchliche experimentelle Daten angesehen werden, und diejenigen, für die |a - A bei t na 2 .
Sei für den Parameter A Es liegt eine unvoreingenommene Schätzung vor A. Wenn wir das Gesetz der Mengenverteilung kennen würden A, wäre die Aufgabe, ein Konfidenzintervall zu finden, sehr einfach: Es würde ausreichen, einen Wert s zu finden, für den
![]()
Die Schwierigkeit besteht darin, dass das Gesetz der Verteilung von Schätzungen gilt A hängt vom Verteilungsgesetz der Menge ab X und daher auf seinen unbekannten Parametern (insbesondere auf dem Parameter selbst). A).
Um diese Schwierigkeit zu umgehen, können Sie die folgende grobe Näherungstechnik verwenden: Ersetzen Sie die unbekannten Parameter im Ausdruck für s durch ihre Punktschätzungen. Mit relativ vielen Experimenten P(ca. 20...30) Diese Technik liefert in der Regel Ergebnisse, die hinsichtlich der Genauigkeit zufriedenstellend sind.
Betrachten Sie als Beispiel das Problem eines Konfidenzintervalls für den mathematischen Erwartungswert.
Lass es entstehen P X, deren Merkmale die mathematische Erwartung sind T und Varianz D- Unbekannt. Für diese Parameter wurden folgende Schätzungen erhalten:

Es ist erforderlich, ein Konfidenzintervall / p zu konstruieren, das der Konfidenzwahrscheinlichkeit p für die mathematische Erwartung entspricht T Mengen X.
Bei der Lösung dieses Problems nutzen wir die Tatsache, dass die Menge T stellt die Summe dar P unabhängige identisch verteilte Zufallsvariablen X h und nach dem zentralen Grenzwertsatz für eine ausreichend große P sein Verteilungsgesetz ist nahezu normal. In der Praxis kann das Verteilungsgesetz der Summe selbst bei einer relativ kleinen Anzahl von Termen (ca. 10...20) annähernd als normal angesehen werden. Wir gehen davon aus, dass der Wert T nach dem Normalgesetz verteilt. Die Merkmale dieses Gesetzes – mathematischer Erwartungswert und Varianz – sind jeweils gleich T Und
(siehe Kapitel 13 Unterabschnitt 13.3). Nehmen wir an, dass der Wert D wir wissen und werden einen Wert Ep finden, für den
Mithilfe der Formel (6.3.5) aus Kapitel 6 drücken wir die Wahrscheinlichkeit auf der linken Seite von (14.3.5) durch die Normalverteilungsfunktion aus
Wo ist die Standardabweichung der Schätzung? T.
Aus Gl.

Finden Sie den Wert von Sp: 
wobei arg Ф* (х) die Umkehrfunktion von Ф* ist (X), diese. ein solcher Wert des Arguments, für den die Normalverteilungsfunktion gleich ist X.
Streuung D, durch die die Menge ausgedrückt wird A 1P, wir wissen es nicht genau; Als Näherungswert können Sie die Schätzung verwenden D(14.3.4) und ungefähr ausdrücken:

Damit ist das Problem der Konstruktion eines Konfidenzintervalls annähernd gelöst, das gleich ist:
wobei gp durch die Formel (14.3.7) bestimmt wird.
Um eine umgekehrte Interpolation in den Tabellen der Funktion Ф* (l) bei der Berechnung von s p zu vermeiden, ist es zweckmäßig, eine spezielle Tabelle (Tabelle 14.3.1) zu erstellen, die die Werte der Größe angibt
abhängig von r. Der Wert (p bestimmt für das Normalengesetz die Anzahl der Standardabweichungen, die rechts und links vom Streuungszentrum aufgetragen werden müssen, damit die Wahrscheinlichkeit, in den resultierenden Bereich zu gelangen, gleich p ist.
Unter Verwendung des Werts 7 p wird das Konfidenzintervall wie folgt ausgedrückt:

Tabelle 14.3.1
Beispiel 1. Es wurden 20 Experimente mit der Menge durchgeführt X; Die Ergebnisse sind in der Tabelle dargestellt. 14.3.2.
Tabelle 14.3.2
Es ist erforderlich, eine Schätzung für die mathematische Erwartung der Menge zu finden X und konstruieren Sie ein Konfidenzintervall, das der Konfidenzwahrscheinlichkeit p = 0,8 entspricht.
Lösung. Wir haben:

Wenn wir l: = 10 als Referenzpunkt wählen und die dritte Formel (14.2.14) verwenden, finden wir die erwartungstreue Schätzung D :

Laut Tabelle 14.3.1 finden wir ![]()
![]()
Grenzen des Selbstvertrauens:

Konfidenzintervall:
![]()
Parameterwerte T, Die in diesem Intervall liegenden Werte sind mit den in der Tabelle angegebenen experimentellen Daten kompatibel. 14.3.2.
Auf ähnliche Weise kann ein Konfidenzintervall für die Varianz konstruiert werden.
Lass es entstehen P unabhängige Experimente mit einer Zufallsvariablen X mit unbekannten Parametern für A und Dispersion D Es wurde eine unvoreingenommene Schätzung erhalten:


Es ist erforderlich, näherungsweise ein Konfidenzintervall für die Varianz zu konstruieren.
Aus Formel (14.3.11) geht hervor, dass die Menge D repräsentiert
Menge P Zufallsvariablen der Form . Diese Werte sind es nicht
unabhängig, da jeder von ihnen die Menge enthält T, von allen anderen abhängig. Es kann jedoch gezeigt werden, dass mit zunehmender P auch das Verteilungsgesetz ihrer Summe nähert sich dem Normalzustand. Fast um P= 20...30 kann es bereits als normal angesehen werden.
Nehmen wir an, dass dies so ist, und finden wir die Merkmale dieses Gesetzes: mathematische Erwartung und Streuung. Seit der Beurteilung D- also unvoreingenommen M[D] = D.
Varianzberechnung D D ist mit relativ komplexen Berechnungen verbunden, daher präsentieren wir seinen Ausdruck ohne Ableitung:
wobei q 4 das vierte Zentralmoment der Größe ist X.
Um diesen Ausdruck zu verwenden, müssen Sie die Werte \u003d 4 und ersetzen D(zumindest nahestehende). Anstatt D Sie können seine Einschätzung verwenden D. Prinzipiell kann das vierte zentrale Moment auch durch eine Schätzung ersetzt werden, beispielsweise einen Wert der Form:

Ein solcher Ersatz führt jedoch zu einer äußerst geringen Genauigkeit, da im Allgemeinen bei einer begrenzten Anzahl von Experimenten Momente höherer Ordnung mit großen Fehlern bestimmt werden. In der Praxis kommt es jedoch häufig vor, dass die Art der Mengenverteilung gesetzmäßig ist X im Voraus bekannt: Nur seine Parameter sind unbekannt. Dann können Sie versuchen, μ 4 durch auszudrücken D.
Nehmen wir den häufigsten Fall, nämlich den Wert X nach dem Normalgesetz verteilt. Dann wird sein viertes zentrales Moment als Streuung ausgedrückt (siehe Kapitel 6, Unterabschnitt 6.2);
![]()
und Formel (14.3.12) ergibt  oder
oder
Ersetzen des Unbekannten in (14.3.14) D seine Einschätzung D, wir bekommen: von wo 
Moment μ 4 kann ausgedrückt werden durch D auch in einigen anderen Fällen, wenn die Verteilung des Wertes X ist nicht normal, aber sein Aussehen ist bekannt. Für das Gesetz der gleichmäßigen Dichte (siehe Kapitel 5) gilt beispielsweise: 
wobei (a, P) das Intervall ist, in dem das Gesetz angegeben ist.
Somit,
![]()
Mit der Formel (14.3.12) erhalten wir:  Wo finden wir ungefähr
Wo finden wir ungefähr
In Fällen, in denen die Art des Verteilungsgesetzes für die Größe 26 unbekannt ist, wird bei der ungefähren Schätzung des Wertes a/) dennoch empfohlen, die Formel (14.3.16) zu verwenden, es sei denn, es gibt besondere Gründe für die Annahme, dass dieses Gesetz gilt unterscheidet sich stark vom Normalzustand (hat eine auffällige positive oder negative Wölbung).
Wenn der Näherungswert a/) auf die eine oder andere Weise erhalten wird, können wir ein Konfidenzintervall für die Varianz auf die gleiche Weise konstruieren, wie wir es für den mathematischen Erwartungswert erstellt haben:
wobei sich der von der gegebenen Wahrscheinlichkeit p abhängige Wert gemäß der Tabelle ergibt. 14.3.1.
Beispiel 2. Finden Sie ein Konfidenzintervall von etwa 80 % für die Varianz einer Zufallsvariablen X unter den Bedingungen von Beispiel 1, wenn bekannt ist, dass der Wert X nach einem nahezu normalen Gesetz verteilt.
Lösung. Der Wert bleibt derselbe wie in der Tabelle. 14.3.1:
![]()
Nach der Formel (14.3.16)

Mit der Formel (14.3.18) ermitteln wir das Konfidenzintervall:
![]()
Der entsprechende Bereich der Standardabweichungswerte: (0,21; 0,29).
14.4. Genaue Methoden zur Konstruktion von Konfidenzintervallen für die Parameter einer nach einem Normalgesetz verteilten Zufallsvariablen
Im vorherigen Unterabschnitt haben wir grobe Näherungsmethoden zur Konstruktion von Konfidenzintervallen für mathematische Erwartung und Varianz untersucht. Hier geben wir eine Vorstellung von den genauen Methoden zur Lösung desselben Problems. Wir betonen, dass es zur genauen Bestimmung von Konfidenzintervallen unbedingt erforderlich ist, die Form des Verteilungsgesetzes der Größe im Voraus zu kennen X, während dies für die Anwendung von Näherungsmethoden nicht erforderlich ist.
Die Idee genauer Methoden zur Konstruktion von Konfidenzintervallen läuft auf Folgendes hinaus. Jedes Konfidenzintervall ergibt sich aus einer Bedingung, die die Wahrscheinlichkeit der Erfüllung bestimmter Ungleichungen ausdrückt, zu denen auch die Schätzung gehört, an der wir interessiert sind A. Gesetz der Wertverteilung A im allgemeinen Fall hängt von unbekannten Parametern der Größe ab X. Manchmal ist es jedoch möglich, Ungleichungen aus einer Zufallsvariablen zu übergeben A zu einer anderen Funktion beobachteter Werte X p X 2, ..., X p. deren Verteilungsgesetz nicht von unbekannten Parametern abhängt, sondern nur von der Anzahl der Experimente und von der Art des Verteilungsgesetzes der Größe abhängt X. Solche Zufallsvariablen spielen in der mathematischen Statistik eine wichtige Rolle; Am ausführlichsten wurden sie für den Fall einer Normalverteilung der Menge untersucht X.
Beispielsweise ist dies bei einer Normalverteilung des Wertes nachgewiesen X Zufallswert

gehorcht dem sogenannten Studentenverteilungsrecht Mit P- 1 Freiheitsgrad; Die Dichte dieses Gesetzes hat die Form

wobei G(x) die bekannte Gammafunktion ist:

Es wurde auch nachgewiesen, dass die Zufallsvariable
hat eine „%2-Verteilung“ mit P- 1 Freiheitsgrad (siehe Kapitel 7), dessen Dichte durch die Formel ausgedrückt wird

Ohne auf die Ableitungen der Verteilungen (14.4.2) und (14.4.4) einzugehen, zeigen wir, wie sie bei der Konstruktion von Konfidenzintervallen für Parameter angewendet werden können Ty D.
Lass es entstehen P unabhängige Experimente mit einer Zufallsvariablen X, normalverteilt mit unbekannten Parametern ZU. Für diese Parameter wurden Schätzungen eingeholt

Es ist erforderlich, Konfidenzintervalle für beide Parameter zu konstruieren, die der Konfidenzwahrscheinlichkeit p entsprechen.
Konstruieren wir zunächst ein Konfidenzintervall für den mathematischen Erwartungswert. Es ist natürlich, dieses Intervall symmetrisch zu nehmen T; sei s p die halbe Länge des Intervalls. Der Wert sp muss so gewählt werden, dass die Bedingung erfüllt ist
Versuchen wir, uns ausgehend von der Zufallsvariablen auf der linken Seite der Gleichheit (14.4.5) zu bewegen T zu einer Zufallsvariablen T, nach Studentenrecht verteilt. Multiplizieren Sie dazu beide Seiten der Ungleichung |m-w?|
durch einen positiven Wert:  oder, unter Verwendung der Notation (14.4.1),
oder, unter Verwendung der Notation (14.4.1),

Suchen wir eine Zahl / p, sodass der Wert / p aus der Bedingung ermittelt werden kann

Aus Formel (14.4.2) geht hervor, dass (1) eine gerade Funktion ist, daher ergibt sich (14.4.8). 
Gleichheit (14.4.9) bestimmt den Wert / p in Abhängigkeit von p. Wenn Ihnen eine Tabelle mit Integralwerten zur Verfügung steht

dann kann der Wert von /p durch umgekehrte Interpolation in der Tabelle gefunden werden. Es ist jedoch bequemer, im Voraus eine Tabelle mit /p-Werten zu erstellen. Eine solche Tabelle finden Sie im Anhang (Tabelle 5). Diese Tabelle zeigt die Werte in Abhängigkeit vom Konfidenzniveau p und der Anzahl der Freiheitsgrade P- 1. Nachdem ich / p aus der Tabelle ermittelt habe. 5 und vorausgesetzt 
Wir finden die halbe Breite des Konfidenzintervalls / p und das Intervall selbst
Beispiel 1. 5 unabhängige Experimente wurden mit einer Zufallsvariablen durchgeführt X, normalverteilt mit unbekannten Parametern T und über. Die Ergebnisse der Experimente sind in der Tabelle aufgeführt. 14.4.1.
Tabelle 14.4.1
Bewertung finden T für die mathematische Erwartung und konstruieren Sie dafür ein 90 %-Konfidenzintervall / p (d. h. das Intervall, das der Konfidenzwahrscheinlichkeit p = 0,9 entspricht).
Lösung. Wir haben:
![]()
Gemäß Tabelle 5 des Antrags auf P - 1 = 4 und p = 0,9 finden wir ![]() Wo
Wo 
Das Konfidenzintervall beträgt
Beispiel 2. Für die Bedingungen von Beispiel 1 von Unterabschnitt 14.3 wird der Wert angenommen X normalverteilt ist, ermitteln Sie das genaue Konfidenzintervall.
Lösung. Gemäß Tabelle 5 des Anhangs finden wir wann P - 1 = 19ir =
0,8 / p = 1,328; von hier 
Beim Vergleich mit der Lösung von Beispiel 1 von Unterabschnitt 14.3 (e p = 0,072) sind wir überzeugt, dass die Diskrepanz sehr unbedeutend ist. Wenn wir die Genauigkeit bis zur zweiten Dezimalstelle beibehalten, stimmen die mit der exakten und der Näherungsmethode ermittelten Konfidenzintervalle überein:
![]()
Fahren wir mit der Erstellung eines Konfidenzintervalls für die Varianz fort. Betrachten Sie den erwartungstreuen Varianzschätzer

und drücken Sie die Zufallsvariable aus D durch Größe V(14.4.3), mit Verteilung x 2 (14.4.4):

Kenntnis des Gesetzes der Mengenverteilung V, Sie können das Intervall /(1) finden, in das es mit einer gegebenen Wahrscheinlichkeit p fällt.
Verteilungsgesetz kn_x(v) Die Größe I 7 hat die in Abb. gezeigte Form. 14.4.1.

Reis. 14.4.1
Es stellt sich die Frage: Wie wählt man das Intervall / p? Wenn das Gesetz der Größenverteilung gilt V symmetrisch wäre (wie das Normalgesetz oder die Student-Verteilung), wäre es natürlich, das Intervall /p symmetrisch in Bezug auf die mathematische Erwartung anzunehmen. In diesem Fall das Gesetz k p_x (v) asymmetrisch. Lassen Sie uns vereinbaren, das Intervall /p so zu wählen, dass die Wahrscheinlichkeit des Wertes beträgt V jenseits des Intervalls nach rechts und links (schattierte Bereiche in Abb. 14.4.1) waren gleich und gleich

Um ein Intervall /p mit dieser Eigenschaft zu konstruieren, verwenden wir die Tabelle. 4 Anwendungen: Es enthält Zahlen y) so dass
![]()
für den Wert V, mit x 2 -Verteilung mit r Freiheitsgraden. In unserem Fall r = n- 1. Lassen Sie uns das Problem beheben r = n- 1 und suchen Sie in der entsprechenden Zeile der Tabelle. 4 zwei Bedeutungen x 2 - eines entspricht der Wahrscheinlichkeit, das andere der Wahrscheinlichkeit. Lassen Sie uns diese bezeichnen
Werte um 2 Und XL? Das Intervall hat Jahr 2, mit deiner Linken, und y~ rechtes Ende.
Finden wir nun aus dem Intervall / p das gewünschte Konfidenzintervall /| für die Dispersion mit den Grenzen D und D2, was den Punkt abdeckt D mit Wahrscheinlichkeit p: ![]()
Konstruieren wir ein Intervall / (, = (?> ü А), das den Punkt abdeckt D genau dann, wenn der Wert V fällt in das Intervall /r. Zeigen wir das Intervall

erfüllt diese Bedingung. Tatsächlich, die Ungleichheiten  sind gleichbedeutend mit Ungleichungen
sind gleichbedeutend mit Ungleichungen
![]()
und diese Ungleichungen werden mit der Wahrscheinlichkeit p erfüllt. Somit wurde das Konfidenzintervall für die Varianz gefunden und wird durch die Formel (14.4.13) ausgedrückt.
Beispiel 3. Finden Sie das Konfidenzintervall für die Varianz unter den Bedingungen von Beispiel 2 von Unterabschnitt 14.3, wenn der Wert bekannt ist X normal verteilt.
Lösung. Wir haben ![]() . Gemäß Tabelle 4 des Anhangs
. Gemäß Tabelle 4 des Anhangs
wir finden bei r = n - 1 = 19

Mit der Formel (14.4.13) ermitteln wir das Konfidenzintervall für die Varianz ![]()
Das entsprechende Intervall für die Standardabweichung beträgt (0,21; 0,32). Dieses Intervall überschreitet nur geringfügig das Intervall (0,21; 0,29), das in Beispiel 2 von Unterabschnitt 14.3 mit der Näherungsmethode ermittelt wurde.
- Abbildung 14.3.1 betrachtet ein Konfidenzintervall symmetrisch zu a. Im Allgemeinen ist dies, wie wir später sehen werden, nicht notwendig.
Eine der Methoden zur Lösung statistischer Probleme ist die Berechnung des Konfidenzintervalls. Sie wird als bevorzugte Alternative zur Punktschätzung verwendet, wenn die Stichprobengröße klein ist. Es ist zu beachten, dass die Berechnung des Konfidenzintervalls selbst recht komplex ist. Aber Excel-Tools machen es etwas einfacher. Lassen Sie uns herausfinden, wie dies in der Praxis geschieht.
Diese Methode wird zur Intervallschätzung verschiedener statistischer Größen verwendet. Die Hauptaufgabe dieser Berechnung besteht darin, die Unsicherheiten der Punktschätzung zu beseitigen.
In Excel gibt es zwei Hauptoptionen für die Durchführung von Berechnungen mit dieser Methode: wenn die Varianz bekannt ist und wenn sie unbekannt ist. Im ersten Fall wird die Funktion für Berechnungen verwendet VERTRAUEN.NORM, und im zweiten - TREUHÄNDER.STUDENT.
Methode 1: CONFIDENCE NORM-Funktion
Operator VERTRAUEN.NORM, das zur statistischen Funktionsgruppe gehört, erschien erstmals in Excel 2010. Frühere Versionen dieses Programms verwenden sein Analogon VERTRAUEN. Der Zweck dieses Operators besteht darin, ein normalverteiltes Konfidenzintervall für den Grundgesamtheitsmittelwert zu berechnen.
Seine Syntax ist wie folgt:
CONFIDENCE.NORM(alpha;standard_off;size)
"Alpha"– ein Argument, das das Signifikanzniveau angibt, das zur Berechnung des Konfidenzniveaus verwendet wird. Das Konfidenzniveau entspricht dem folgenden Ausdruck:
(1-"Alpha")*100
"Standardabweichung"- Dies ist ein Argument, dessen Kern schon aus dem Namen hervorgeht. Dies ist die Standardabweichung der vorgeschlagenen Stichprobe.
"Größe"– Argument, das die Stichprobengröße definiert.
Alle Argumente für diesen Operator sind erforderlich.
Funktion VERTRAUEN hat genau die gleichen Argumente und Möglichkeiten wie der vorherige. Seine Syntax ist:
VERTRAUEN(alpha, standard_off, size)
Wie Sie sehen, bestehen die Unterschiede lediglich im Namen des Betreibers. Aus Kompatibilitätsgründen wird diese Funktion in Excel 2010 und neueren Versionen in einer speziellen Kategorie belassen "Kompatibilität". In Excel 2007 und früheren Versionen ist es in der Hauptgruppe der statistischen Operatoren enthalten.
Die Grenze des Konfidenzintervalls wird anhand der folgenden Formel ermittelt:
X+(-)VERTRAUENSNORM
Wo X ist der durchschnittliche Stichprobenwert, der in der Mitte des ausgewählten Bereichs liegt.
Schauen wir uns nun anhand eines konkreten Beispiels an, wie man ein Konfidenzintervall berechnet. Es wurden 12 Tests durchgeführt, die zu unterschiedlichen Ergebnissen führten, die in der Tabelle aufgeführt sind. Das ist unsere Gesamtheit. Die Standardabweichung beträgt 8. Wir müssen das Konfidenzintervall auf dem Konfidenzniveau von 97 % berechnen.
- Wählen Sie die Zelle aus, in der das Ergebnis der Datenverarbeitung angezeigt wird. Klicken Sie auf die Schaltfläche „Funktion einfügen“.
- Erscheint Funktionsassistent. Zur Kategorie gehen „Statistisch“ und markieren Sie den Namen „VERTRAUEN.NORM“. Klicken Sie anschließend auf die Schaltfläche "OK".
- Das Argumentfenster wird geöffnet. Seine Felder entsprechen natürlich den Namen der Argumente.
Platzieren Sie den Cursor im ersten Feld - "Alpha". Hier sollten wir das Signifikanzniveau angeben. Wie wir uns erinnern, liegt unser Vertrauensgrad bei 97 %. Gleichzeitig haben wir gesagt, dass es wie folgt berechnet wird:(1-Vertrauensstufe)/100
Das heißt, wenn wir den Wert ersetzen, erhalten wir:
Durch einfache Berechnungen finden wir heraus, dass das Argument "Alpha" gleicht 0,03 . Geben Sie diesen Wert in das Feld ein.
Wie Sie wissen, ist die Standardabweichung gemäß der Bedingung gleich 8 . Deshalb im Feld "Standardabweichung" Notieren Sie sich einfach diese Nummer.
Auf dem Feld "Größe" Sie müssen die Anzahl der durchgeführten Testelemente eingeben. Soweit wir uns erinnern, ihre 12 . Um die Formel jedoch zu automatisieren und sie nicht jedes Mal zu bearbeiten, wenn wir einen neuen Test durchführen, setzen wir diesen Wert nicht mit einer gewöhnlichen Zahl, sondern mit dem Operator ÜBERPRÜFEN. Platzieren wir also den Cursor im Feld "Größe" und klicken Sie dann auf das Dreieck, das sich links neben der Bearbeitungsleiste befindet.
Es erscheint eine Liste der zuletzt verwendeten Funktionen. Wenn der Betreiber ÜBERPRÜFEN kürzlich von Ihnen verwendet wurde, sollte es auf dieser Liste stehen. In diesem Fall müssen Sie nur auf den Namen klicken. Andernfalls, wenn Sie es nicht finden, kommen Sie zur Sache "Andere Funktionen...".
- Ein bereits bekannter erscheint Funktionsassistent. Kommen wir noch einmal zurück zur Gruppe „Statistisch“. Wir markieren dort den Namen "ÜBERPRÜFEN". Klicken Sie auf die Schaltfläche "OK".
- Das Argumentfenster für die obige Anweisung wird angezeigt. Diese Funktion dient dazu, die Anzahl der Zellen in einem angegebenen Bereich zu berechnen, die numerische Werte enthalten. Seine Syntax ist wie folgt:
COUNT(Wert1,Wert2,…)
Argumentgruppe "Werte" ist ein Verweis auf den Bereich, in dem Sie die Anzahl der mit numerischen Daten gefüllten Zellen berechnen möchten. Insgesamt kann es bis zu 255 solcher Argumente geben, in unserem Fall benötigen wir jedoch nur eines.
Platzieren Sie den Cursor im Feld „Wert1“ und wählen Sie mit gedrückter linker Maustaste auf dem Blatt den Bereich aus, der unsere Sammlung enthält. Anschließend wird seine Adresse im Feld angezeigt. Klicken Sie auf die Schaltfläche "OK".
- Danach führt die Anwendung die Berechnung durch und zeigt das Ergebnis in der Zelle an, in der es sich befindet. In unserem speziellen Fall sah die Formel so aus:
VERTRAUENSNORM(0,03,8,COUNT(B2:B13))
Das Gesamtergebnis der Berechnungen war 5,011609 .
- Aber das ist noch nicht alles. Wie wir uns erinnern, wird die Grenze des Konfidenzintervalls berechnet, indem das Berechnungsergebnis zum Stichprobenmittelwert addiert und davon subtrahiert wird VERTRAUEN.NORM. Auf diese Weise werden jeweils die rechte und linke Grenze des Konfidenzintervalls berechnet. Der Stichprobenmittelwert selbst kann mithilfe des Operators berechnet werden DURCHSCHNITT.
Dieser Operator dient zur Berechnung des arithmetischen Mittels eines ausgewählten Zahlenbereichs. Es hat die folgende recht einfache Syntax:
DURCHSCHNITT(Anzahl1,Anzahl2,…)
Streit "Nummer" kann entweder ein einzelner numerischer Wert oder ein Verweis auf Zellen oder sogar ganze Bereiche sein, die diese enthalten.
Wählen Sie also die Zelle aus, in der die Berechnung des Durchschnittswerts angezeigt werden soll, und klicken Sie auf die Schaltfläche „Funktion einfügen“.
- Öffnet Funktionsassistent. Zurück zur Kategorie „Statistisch“ und wählen Sie einen Namen aus der Liste aus "DURCHSCHNITT". Klicken Sie wie immer auf den Button "OK".
- Das Argumentfenster wird geöffnet. Platzieren Sie den Cursor im Feld "Nummer 1" Wählen Sie bei gedrückter linker Maustaste den gesamten Wertebereich aus. Nachdem die Koordinaten im Feld angezeigt werden, klicken Sie auf die Schaltfläche "OK".
- Danach DURCHSCHNITT zeigt das Berechnungsergebnis in einem Blattelement an.
- Wir berechnen die rechte Grenze des Konfidenzintervalls. Wählen Sie dazu eine separate Zelle aus und setzen Sie das Zeichen «=»
und addieren Sie die Inhalte der Blattelemente, in denen sich die Ergebnisse von Funktionsberechnungen befinden DURCHSCHNITT Und VERTRAUEN.NORM. Um die Berechnung durchzuführen, drücken Sie die Taste Eingeben. In unserem Fall haben wir die folgende Formel erhalten:
Berechnungsergebnis: 6,953276
- Auf die gleiche Weise berechnen wir die linke Grenze des Konfidenzintervalls, nur dieses Mal aus dem Ergebnis der Berechnung DURCHSCHNITT Subtrahieren Sie das Ergebnis der Operatorberechnung VERTRAUEN.NORM. Die resultierende Formel für unser Beispiel ist vom folgenden Typ:
Berechnungsergebnis: -3,06994
- Wir haben versucht, alle Schritte zur Berechnung des Konfidenzintervalls detailliert zu beschreiben, daher haben wir jede Formel ausführlich beschrieben. Sie können aber alle Aktionen in einer Formel kombinieren. Die Berechnung der rechten Grenze des Konfidenzintervalls kann wie folgt geschrieben werden:
DURCHSCHNITT(B2:B13)+KONFIDENZ.NORM(0,03,8,ANZAHL(B2:B13))
- Eine ähnliche Berechnung für den linken Rand würde so aussehen:
AVERAGE(B2:B13)-CONFIDENCE.NORM(0.03,8,COUNT(B2:B13))














Methode 2: Funktion VERTRAUENSWÜRDIGER STUDENT
Darüber hinaus verfügt Excel über eine weitere Funktion, die mit der Berechnung des Konfidenzintervalls verbunden ist – TREUHÄNDER.STUDENT. Es erschien nur in Excel 2010. Dieser Operator berechnet das Konfidenzintervall der Grundgesamtheit mithilfe der Student-Verteilung. Es ist sehr praktisch, es zu verwenden, wenn die Varianz und dementsprechend die Standardabweichung unbekannt sind. Die Operatorsyntax lautet:
CONFIDENCE.STUDENT(alpha,standard_off,size)
Wie Sie sehen, blieben die Namen der Betreiber in diesem Fall unverändert.
Sehen wir uns an, wie man die Grenzen eines Konfidenzintervalls mit einer unbekannten Standardabweichung am Beispiel derselben Grundgesamtheit berechnet, die wir in der vorherigen Methode betrachtet haben. Nehmen wir den Vertrauensgrad wie beim letzten Mal mit 97 % an.
- Wählen Sie die Zelle aus, in der die Berechnung durchgeführt werden soll. Klicken Sie auf die Schaltfläche „Funktion einfügen“.
- Im geöffneten Funktionsassistent gehe zur Kategorie „Statistisch“. Wählen Sie einen Namen „VERTRAUENSWÜRDIGER STUDIERENDER“. Klicken Sie auf die Schaltfläche "OK".
- Das Argumentfenster für den angegebenen Operator wird geöffnet.
Auf dem Feld "Alpha" Da das Konfidenzniveau 97 % beträgt, notieren wir die Zahl 0,03 . Zum zweiten Mal werden wir uns nicht mit den Prinzipien der Berechnung dieses Parameters befassen.
Platzieren Sie anschließend den Cursor im Feld "Standardabweichung". Diesmal ist uns dieser Indikator unbekannt und muss berechnet werden. Dies geschieht über eine spezielle Funktion - STDEV.V. Um das Fenster dieses Operators zu öffnen, klicken Sie auf das Dreieck links neben der Bearbeitungsleiste. Sollten wir den gewünschten Namen in der sich öffnenden Liste nicht finden, dann gehen Sie zum Punkt "Andere Funktionen...".
- Beginnt Funktionsassistent. Zur Kategorie wechseln „Statistisch“ und markiere den Namen darin „STDEV.V“. Klicken Sie dann auf den Button "OK".
- Das Argumentfenster wird geöffnet. Die Aufgabe des Bedieners STDEV.V besteht darin, die Standardabweichung einer Stichprobe zu bestimmen. Seine Syntax sieht so aus:
STANDARDABWEICHUNG.B(Anzahl1;Anzahl2;…)
Es ist nicht schwer, das Argument zu erraten "Nummer" ist die Adresse des Auswahlelements. Wenn die Auswahl in einem einzelnen Array platziert wird, können Sie nur ein Argument verwenden, um einen Link zu diesem Bereich bereitzustellen.
Platzieren Sie den Cursor im Feld "Nummer 1" und wählen Sie wie immer mit gedrückter linker Maustaste die Sammlung aus. Nachdem die Koordinaten im Feld vorliegen, beeilen Sie sich nicht, den Knopf zu drücken "OK", da das Ergebnis falsch sein wird. Zuerst müssen wir zum Fenster mit den Operatorargumenten zurückkehren TREUHÄNDER.STUDENT um das letzte Argument hinzuzufügen. Klicken Sie dazu in der Bearbeitungsleiste auf den entsprechenden Namen.
- Das Argumentfenster für die bereits bekannte Funktion öffnet sich erneut. Platzieren Sie den Cursor im Feld "Größe". Klicken Sie erneut auf das uns bereits bekannte Dreieck, um zur Auswahl der Operatoren zu gelangen. Wie Sie verstehen, brauchen wir einen Namen "ÜBERPRÜFEN". Da wir diese Funktion in den Berechnungen der vorherigen Methode verwendet haben, ist sie in dieser Liste vorhanden, also klicken Sie einfach darauf. Wenn Sie es nicht finden, befolgen Sie den in der ersten Methode beschriebenen Algorithmus.
- Einmal im Argumentfenster ÜBERPRÜFEN, platzieren Sie den Cursor im Feld "Nummer 1" und wählen Sie mit gedrückter Maustaste die Sammlung aus. Klicken Sie dann auf den Button "OK".
- Anschließend führt das Programm eine Berechnung durch und zeigt den Wert des Konfidenzintervalls an.
- Um die Grenzen zu bestimmen, müssen wir erneut den Stichprobenmittelwert berechnen. Aber vorausgesetzt, der Berechnungsalgorithmus verwendet die Formel DURCHSCHNITT das gleiche wie bei der vorherigen Methode, und auch wenn sich das Ergebnis nicht geändert hat, werden wir nicht ein zweites Mal im Detail darauf eingehen.
- Addieren der Berechnungsergebnisse DURCHSCHNITT Und TREUHÄNDER.STUDENT erhalten wir die richtige Grenze des Konfidenzintervalls.
- Subtrahieren von den Berechnungsergebnissen des Operators DURCHSCHNITT Berechnungsergebnis TREUHÄNDER.STUDENT, wir haben die linke Grenze des Konfidenzintervalls.
- Wenn die Berechnung in einer Formel geschrieben wird, sieht die Berechnung der rechten Grenze in unserem Fall so aus:
DURCHSCHNITT(B2:B13)+VERTRAUEN.STUDENT(0.03,STDEV.B(B2:B13),ANZAHL(B2:B13))
- Dementsprechend sieht die Formel zur Berechnung des linken Randes so aus:
AVERAGE(B2:B13)-CONFIDENCE.STUDENT(0.03,STDEV.B(B2:B13),COUNT(B2:B13))













Wie Sie sehen, erleichtern Excel-Tools die Berechnung des Konfidenzintervalls und seiner Grenzen erheblich. Zu diesem Zweck werden separate Operatoren für Stichproben verwendet, deren Varianz bekannt und unbekannt ist.
Vertrauensintervalle.
Die Berechnung des Konfidenzintervalls basiert auf dem durchschnittlichen Fehler des entsprechenden Parameters. Konfidenzintervall zeigt, innerhalb welcher Grenzen mit Wahrscheinlichkeit (1-a) der wahre Wert des geschätzten Parameters liegt. Hier ist a das Signifikanzniveau, (1-a) wird auch als Konfidenzwahrscheinlichkeit bezeichnet.
Im ersten Kapitel haben wir gezeigt, dass beispielsweise beim arithmetischen Mittel der wahre Mittelwert der Grundgesamtheit in etwa 95 % der Fälle innerhalb von 2 Standardfehlern vom Mittelwert liegt. Daher liegen die Grenzen des 95 %-Konfidenzintervalls für den Mittelwert um den doppelten mittleren Fehler des Mittelwerts vom Stichprobenmittelwert entfernt, d. h. Wir multiplizieren den durchschnittlichen Fehler des Mittelwerts mit einem bestimmten Koeffizienten, abhängig vom Konfidenzniveau. Für den Durchschnitt und die Differenz der Durchschnittswerte wird der Student-Koeffizient (der kritische Wert des Student-Tests) verwendet, für den Anteil und die Differenz der Anteile der kritische Wert des Z-Kriteriums. Das Produkt aus Koeffizient und durchschnittlichem Fehler kann als maximaler Fehler eines bestimmten Parameters bezeichnet werden, d.h. das Maximum, das wir bei der Beurteilung erreichen können.
Konfidenzintervall für arithmetisches Mittel : .
Hier ist der Stichprobenmittelwert;
Durchschnittlicher Fehler des arithmetischen Mittels;
S - Stichprobenstandardabweichung;
N
f = n-1 (Studentenkoeffizient).
Konfidenzintervall für Unterschiede der arithmetischen Mittelwerte :
Hier ist der Unterschied zwischen den Stichprobenmittelwerten;
 - durchschnittlicher Fehler der Differenz zwischen arithmetischen Mitteln;
- durchschnittlicher Fehler der Differenz zwischen arithmetischen Mitteln;
s 1 , s 2 – Stichprobenstandardabweichungen;
n1,n2
Der kritische Wert des Student-Tests für ein gegebenes Signifikanzniveau a und die Anzahl der Freiheitsgrade f=n 1 +n 2-2 (Studentenkoeffizient).
Konfidenzintervall für Anteile :
![]() .
.
Hier ist d der Probenanteil;
– durchschnittlicher Bruchfehler;
N– Stichprobengröße (Gruppengröße);
Konfidenzintervall für Differenz der Anteile :
Hier ist der Unterschied bei den Beispielanteilen;
 – durchschnittlicher Fehler der Differenz zwischen arithmetischen Mitteln;
– durchschnittlicher Fehler der Differenz zwischen arithmetischen Mitteln;
n1,n2– Probenvolumina (Anzahl der Gruppen);
Der kritische Wert des Z-Kriteriums bei einem bestimmten Signifikanzniveau a ( , , ).
Durch die Berechnung von Konfidenzintervallen für die Differenz zwischen Indikatoren sehen wir zunächst direkt die möglichen Werte des Effekts und nicht nur seine Punktschätzung. Zweitens können wir eine Schlussfolgerung über die Akzeptanz oder Ablehnung der Nullhypothese ziehen und drittens können wir eine Schlussfolgerung über die Aussagekraft des Tests ziehen.
Beim Testen von Hypothesen mithilfe von Konfidenzintervallen müssen Sie die folgende Regel beachten:
Wenn das 100(1-a)-Prozent-Konfidenzintervall der Mittelwertdifferenz nicht Null enthält, sind die Unterschiede auf Signifikanzniveau a statistisch signifikant; im Gegenteil, wenn dieses Intervall Null enthält, dann sind die Unterschiede statistisch nicht signifikant.
Wenn dieses Intervall tatsächlich Null enthält, bedeutet dies, dass der verglichene Indikator in einer der Gruppen im Vergleich zur anderen entweder größer oder kleiner sein kann, d. h. Die beobachteten Unterschiede sind zufällig.
Die Aussagekraft des Tests kann anhand der Position von Null innerhalb des Konfidenzintervalls beurteilt werden. Liegt Null nahe an der Unter- oder Obergrenze des Intervalls, ist es möglich, dass die Unterschiede bei einer größeren Anzahl verglichener Gruppen statistische Signifikanz erreichen. Wenn Null nahe der Mitte des Intervalls liegt, bedeutet dies, dass sowohl ein Anstieg als auch ein Rückgang des Indikators in der Versuchsgruppe gleich wahrscheinlich sind und es wahrscheinlich tatsächlich keine Unterschiede gibt.
Beispiele:
Vergleich der chirurgischen Mortalität bei Verwendung zweier verschiedener Anästhesiearten: 61 Personen wurden mit der ersten Anästhesieart operiert, 8 starben, bei der zweiten Art – 67 Personen, starben 10.
d 1 = 8/61 = 0,131; d2 = 10/67 = 0,149; d1-d2 = - 0,018.
Der Unterschied in der Letalität der verglichenen Methoden liegt im Bereich (-0,018 - 0,122; -0,018 + 0,122) oder (-0,14; 0,104) mit einer Wahrscheinlichkeit von 100(1-a) = 95 %. Das Intervall enthält Null, d.h. Die Hypothese einer gleichen Sterblichkeit bei zwei verschiedenen Anästhesiearten kann nicht abgelehnt werden.
Somit kann und wird die Sterblichkeitsrate mit einer Wahrscheinlichkeit von 95 % auf 14 % sinken und auf 10,4 % ansteigen, d. h. Null liegt ungefähr in der Mitte des Intervalls, daher kann argumentiert werden, dass sich diese beiden Methoden höchstwahrscheinlich nicht wirklich in der Letalität unterscheiden.
In dem zuvor besprochenen Beispiel wurde die durchschnittliche Presszeit während des Klopftests in vier Gruppen von Studenten verglichen, die sich in den Prüfungsergebnissen unterschieden. Berechnen wir die Konfidenzintervalle für die durchschnittliche Presszeit für Schüler, die die Prüfung mit den Noten 2 und 5 bestanden haben, und das Konfidenzintervall für die Differenz zwischen diesen Durchschnittswerten.
Die Student-Koeffizienten werden mithilfe der Student-Verteilungstabellen (siehe Anhang) ermittelt: für die erste Gruppe: = t(0,05;48) = 2,011; für die zweite Gruppe: = t(0,05;61) = 2,000. Somit sind die Konfidenzintervalle für die erste Gruppe: = (162,19-2,011*2,18; 162,19+2,011*2,18) = (157,8; 166,6), für die zweite Gruppe (156,55-2.000*1,88; 156,55+2.000*1,88) = (152,8). ; 160,3). Für diejenigen, die die Prüfung mit 2 bestanden haben, liegt die durchschnittliche Druckzeit also zwischen 157,8 ms und 166,6 ms mit einer Wahrscheinlichkeit von 95 %, für diejenigen, die die Prüfung mit 5 bestanden haben, zwischen 152,8 ms und 160,3 ms mit einer Wahrscheinlichkeit von 95 % .
Sie können die Nullhypothese auch mithilfe von Konfidenzintervallen für Mittelwerte und nicht nur für die Mittelwertdifferenz testen. Wenn sich beispielsweise wie in unserem Fall die Konfidenzintervalle für die Mittelwerte überschneiden, kann die Nullhypothese nicht abgelehnt werden. Um eine Hypothese auf einem gewählten Signifikanzniveau abzulehnen, dürfen sich die entsprechenden Konfidenzintervalle nicht überschneiden.
Lassen Sie uns das Konfidenzintervall für den Unterschied in der durchschnittlichen Presszeit in den Gruppen ermitteln, die die Prüfung mit den Noten 2 und 5 bestanden haben. Durchschnittsunterschied: 162,19 – 156,55 = 5,64. Schülerkoeffizient: = t(0,05;49+62-2) = t(0,05;109) = 1,982. Die Gruppenstandardabweichungen betragen: ; . Wir berechnen den durchschnittlichen Fehler der Differenz zwischen den Mittelwerten: . Konfidenzintervall: =(5,64-1,982*2,87; 5,64+1,982*2,87) = (-0,044; 11,33).
Der Unterschied in der durchschnittlichen Presszeit in den Gruppen, die die Prüfung mit 2 und 5 bestanden haben, liegt also im Bereich von -0,044 ms bis 11,33 ms. Dieses Intervall umfasst Null, d.h. Die durchschnittliche Bearbeitungszeit für diejenigen, die die Prüfung gut bestanden haben, kann sich im Vergleich zu denen, die die Prüfung nicht zufriedenstellend bestanden haben, entweder erhöhen oder verkürzen, d. h. Die Nullhypothese kann nicht abgelehnt werden. Aber Null liegt sehr nahe an der Untergrenze, und bei denjenigen, die gut bestanden haben, ist es viel wahrscheinlicher, dass sich die Presszeit verkürzt. Daraus können wir schließen, dass es immer noch Unterschiede in der durchschnittlichen Presszeit zwischen denen, die 2 und 5 bestanden haben, gibt, wir konnten sie angesichts der Veränderung der durchschnittlichen Zeit, der Streuung der durchschnittlichen Zeit und der Stichprobengrößen jedoch nicht erkennen.
Die Teststärke ist die Wahrscheinlichkeit, eine falsche Nullhypothese abzulehnen, d. h. Finden Sie Unterschiede dort, wo sie tatsächlich existieren.
Die Aussagekraft des Tests wird anhand des Signifikanzniveaus, der Größe der Unterschiede zwischen Gruppen, der Streuung der Werte in Gruppen und der Stichprobengröße bestimmt.
Für den Student-t-Test und die Varianzanalyse können Sensitivitätsdiagramme verwendet werden.
Die Leistung des Kriteriums kann genutzt werden, um vorab die erforderliche Anzahl von Gruppen zu bestimmen.
Das Konfidenzintervall gibt an, innerhalb welcher Grenzen der wahre Wert des geschätzten Parameters mit einer gegebenen Wahrscheinlichkeit liegt.
Mithilfe von Konfidenzintervallen können Sie statistische Hypothesen testen und Rückschlüsse auf die Sensitivität von Kriterien ziehen.
LITERATUR.
Glanz S. – Kapitel 6,7.
Rebrova O.Yu. – S. 112-114, S. 171-173, S. 234-238.
Sidorenko E.V. – S. 32-33.
Fragen zum Selbsttest der Studierenden.
1. Welche Aussagekraft hat das Kriterium?
2. In welchen Fällen ist es notwendig, die Aussagekraft von Kriterien zu bewerten?
3. Methoden zur Leistungsberechnung.
6. Wie testet man eine statistische Hypothese mithilfe eines Konfidenzintervalls?
7. Was lässt sich über die Aussagekraft des Kriteriums bei der Berechnung des Konfidenzintervalls sagen?
Aufgaben.
Ziel– Bringen Sie den Schülern Algorithmen zur Berechnung von Konfidenzintervallen statistischer Parameter bei.
Bei der statistischen Verarbeitung von Daten sollten das berechnete arithmetische Mittel, der Variationskoeffizient, der Korrelationskoeffizient, die Differenzkriterien und andere Punktstatistiken quantitative Konfidenzgrenzen erhalten, die mögliche Schwankungen des Indikators in kleinere und größere Richtungen innerhalb des Konfidenzintervalls anzeigen.
Beispiel 3.1
.
Die Verteilung von Kalzium im Blutserum von Affen wird, wie zuvor festgestellt, durch die folgenden Probenindikatoren charakterisiert: = 11,94 mg %;  = 0,127 mg%; N= 100. Es ist erforderlich, das Konfidenzintervall für den allgemeinen Durchschnitt zu bestimmen (
= 0,127 mg%; N= 100. Es ist erforderlich, das Konfidenzintervall für den allgemeinen Durchschnitt zu bestimmen (  ) mit Konfidenzwahrscheinlichkeit P
= 0,95.
) mit Konfidenzwahrscheinlichkeit P
= 0,95.
Der allgemeine Durchschnitt liegt mit einer bestimmten Wahrscheinlichkeit im Intervall:
 , Wo
, Wo  – arithmetisches Mittel der Stichprobe; T– Schülertest;
– arithmetisches Mittel der Stichprobe; T– Schülertest;  – Fehler des arithmetischen Mittels.
– Fehler des arithmetischen Mittels.
Mithilfe der Tabelle „Student-t-Test-Werte“ ermitteln wir den Wert
 mit einer Konfidenzwahrscheinlichkeit von 0,95 und der Anzahl der Freiheitsgrade k= 100-1 = 99. Es entspricht 1,982. Zusammen mit den Werten des arithmetischen Mittels und des statistischen Fehlers setzen wir ihn in die Formel ein:
mit einer Konfidenzwahrscheinlichkeit von 0,95 und der Anzahl der Freiheitsgrade k= 100-1 = 99. Es entspricht 1,982. Zusammen mit den Werten des arithmetischen Mittels und des statistischen Fehlers setzen wir ihn in die Formel ein:
oder 11.69  12,19
12,19
Somit kann mit einer Wahrscheinlichkeit von 95 % angegeben werden, dass der allgemeine Durchschnitt dieser Normalverteilung zwischen 11,69 und 12,19 mg % liegt.
Beispiel 3.2
. Bestimmen Sie die Grenzen des 95 %-Konfidenzintervalls für die allgemeine Varianz (  ) Verteilung von Kalzium im Blut von Affen, sofern bekannt
) Verteilung von Kalzium im Blut von Affen, sofern bekannt  = 1,60, bei N
= 100.
= 1,60, bei N
= 100.
Um das Problem zu lösen, können Sie die folgende Formel verwenden:
Wo  – statistischer Streuungsfehler.
– statistischer Streuungsfehler.
Wir ermitteln den Stichprobenvarianzfehler mithilfe der Formel:  . Es beträgt 0,11. Bedeutung T- Kriterium mit einer Konfidenzwahrscheinlichkeit von 0,95 und der Anzahl der Freiheitsgrade k= 100–1 = 99 ist aus dem vorherigen Beispiel bekannt.
. Es beträgt 0,11. Bedeutung T- Kriterium mit einer Konfidenzwahrscheinlichkeit von 0,95 und der Anzahl der Freiheitsgrade k= 100–1 = 99 ist aus dem vorherigen Beispiel bekannt.
Verwenden wir die Formel und erhalten:
oder 1,38  1,82
1,82
Genauer gesagt kann das Konfidenzintervall der allgemeinen Varianz mithilfe von konstruiert werden  (Chi-Quadrat) – Pearson-Test. Die kritischen Punkte für dieses Kriterium sind in einer speziellen Tabelle aufgeführt. Bei Verwendung des Kriteriums
(Chi-Quadrat) – Pearson-Test. Die kritischen Punkte für dieses Kriterium sind in einer speziellen Tabelle aufgeführt. Bei Verwendung des Kriteriums  Zur Konstruktion eines Konfidenzintervalls wird ein zweiseitiges Signifikanzniveau verwendet. Für die untere Grenze wird das Signifikanzniveau anhand der Formel berechnet
Zur Konstruktion eines Konfidenzintervalls wird ein zweiseitiges Signifikanzniveau verwendet. Für die untere Grenze wird das Signifikanzniveau anhand der Formel berechnet  , für die Spitze –
, für die Spitze –  . Zum Beispiel für das Konfidenzniveau
. Zum Beispiel für das Konfidenzniveau  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Dementsprechend gemäß der Verteilungstabelle der kritischen Werte
= 0,990. Dementsprechend gemäß der Verteilungstabelle der kritischen Werte  , mit berechnetem Konfidenzniveau und Anzahl der Freiheitsgrade k= 100 – 1= 99, finden Sie die Werte
, mit berechnetem Konfidenzniveau und Anzahl der Freiheitsgrade k= 100 – 1= 99, finden Sie die Werte  Und
Und  . Wir bekommen
. Wir bekommen  entspricht 135,80 und
entspricht 135,80 und 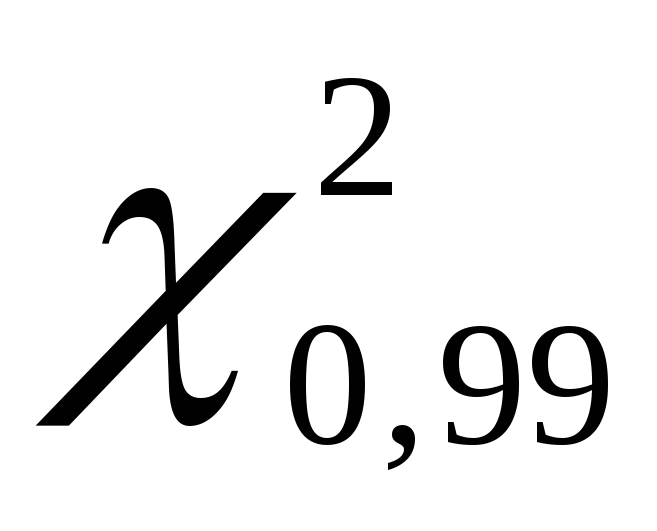 entspricht 70,06.
entspricht 70,06.
Um Konfidenzgrenzen für die allgemeine Varianz zu finden, verwenden Sie  Verwenden wir die Formeln: für die untere Grenze
Verwenden wir die Formeln: für die untere Grenze 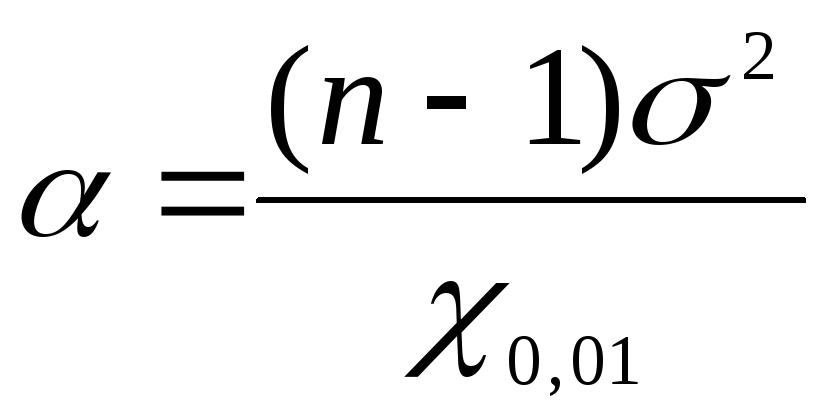 , für die Obergrenze
, für die Obergrenze  . Ersetzen wir die gefundenen Werte durch die Problemdaten
. Ersetzen wir die gefundenen Werte durch die Problemdaten  in Formeln:
in Formeln:  =
1,17;
=
1,17; = 2,26. Also mit einer Konfidenzwahrscheinlichkeit P= 0,99 oder 99 % Die allgemeine Varianz liegt im Bereich von 1,17 bis einschließlich 2,26 mg %.
= 2,26. Also mit einer Konfidenzwahrscheinlichkeit P= 0,99 oder 99 % Die allgemeine Varianz liegt im Bereich von 1,17 bis einschließlich 2,26 mg %.
Beispiel 3.3 . Unter 1000 Weizensamen aus der am Aufzug eingegangenen Charge wurden 120 mit Mutterkorn infizierte Samen gefunden. Es ist notwendig, die wahrscheinlichen Grenzen des allgemeinen Anteils infizierter Samen in einer bestimmten Weizencharge zu bestimmen.
Es empfiehlt sich, die Vertrauensgrenzen für den allgemeinen Anteil für alle seine möglichen Werte nach der Formel zu ermitteln:
 ,
,
Wo N – Anzahl der Beobachtungen; M– absolute Größe einer der Gruppen; T– normalisierte Abweichung.
Der Probenanteil infizierter Samen beträgt  oder 12 %. Mit Konfidenzwahrscheinlichkeit R= 95 % normalisierte Abweichung ( T-Studententest bei k
=
oder 12 %. Mit Konfidenzwahrscheinlichkeit R= 95 % normalisierte Abweichung ( T-Studententest bei k
=
 )T
= 1,960.
)T
= 1,960.
Wir setzen die verfügbaren Daten in die Formel ein:
Daher sind die Grenzen des Konfidenzintervalls gleich  = 0,122–0,041 = 0,081 oder 8,1 %;
= 0,122–0,041 = 0,081 oder 8,1 %;  = 0,122 + 0,041 = 0,163 oder 16,3 %.
= 0,122 + 0,041 = 0,163 oder 16,3 %.
Somit kann mit einer Konfidenzwahrscheinlichkeit von 95 % angegeben werden, dass der allgemeine Anteil infizierter Samen zwischen 8,1 und 16,3 % liegt.
Beispiel 3.4 . Der Variationskoeffizient, der die Variation von Calcium (mg %) im Blutserum von Affen charakterisiert, betrug 10,6 %. Probengröße N= 100. Es ist notwendig, die Grenzen des 95 %-Konfidenzintervalls für den allgemeinen Parameter zu bestimmen Lebenslauf.
Grenzen des Konfidenzintervalls für den allgemeinen Variationskoeffizienten Lebenslauf werden durch die folgenden Formeln bestimmt:
 Und
Und  , Wo K
Zwischenwert berechnet nach der Formel
, Wo K
Zwischenwert berechnet nach der Formel  .
.
Das weiß ich mit großer Wahrscheinlichkeit R= 95 % normalisierte Abweichung (Studententest bei k
=
 )T
= 1,960, berechnen wir zunächst den Wert ZU:
)T
= 1,960, berechnen wir zunächst den Wert ZU:
 .
.
 oder 9,3 %
oder 9,3 %
 oder 12,3 %
oder 12,3 %
Somit liegt der allgemeine Variationskoeffizient mit einem Konfidenzniveau von 95 % im Bereich von 9,3 bis 12,3 %. Bei wiederholten Proben wird der Variationskoeffizient 12,3 % nicht überschreiten und in 95 von 100 Fällen 9,3 % nicht unterschreiten.
Fragen zur Selbstkontrolle:

Probleme zur unabhängigen Lösung.
1. Der durchschnittliche Fettanteil in der Milch während der Laktation von Kholmogory-Kreuzungskühen betrug wie folgt: 3,4; 3,6; 3,2; 3.1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4.1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Legen Sie Konfidenzintervalle für den allgemeinen Mittelwert bei einem Konfidenzniveau von 95 % (20 Punkte) fest.
2. Bei 400 Hybridroggenpflanzen erschienen die ersten Blüten im Durchschnitt 70,5 Tage nach der Aussaat. Die Standardabweichung betrug 6,9 Tage. Bestimmen Sie den Fehler des Mittelwerts und der Konfidenzintervalle für den allgemeinen Mittelwert und die Varianz auf dem Signifikanzniveau W= 0,05 und W= 0,01 (25 Punkte).
3. Bei der Untersuchung der Blattlänge von 502 Exemplaren von Gartenerdbeeren wurden folgende Daten erhalten:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  =± 0,06 cm. Bestimmen Sie Konfidenzintervalle für den arithmetischen Mittelwert der Grundgesamtheit mit Signifikanzniveaus von 0,01; 0,02; 0,05. (25 Punkte).
=± 0,06 cm. Bestimmen Sie Konfidenzintervalle für den arithmetischen Mittelwert der Grundgesamtheit mit Signifikanzniveaus von 0,01; 0,02; 0,05. (25 Punkte).
4. In einer Studie mit 150 erwachsenen Männern betrug die durchschnittliche Körpergröße 167 cm σ = 6 cm. Wo liegen die Grenzen des allgemeinen Mittelwerts und der allgemeinen Varianz bei einer Konfidenzwahrscheinlichkeit von 0,99 und 0,95? (25 Punkte).
5. Die Verteilung von Kalzium im Blutserum von Affen wird durch folgende selektive Indikatoren charakterisiert:
 = 11,94 mg%, σ
= 1,27, N
= 100. Konstruieren Sie ein 95 %-Konfidenzintervall für den allgemeinen Mittelwert dieser Verteilung. Berechnen Sie den Variationskoeffizienten (25 Punkte).
= 11,94 mg%, σ
= 1,27, N
= 100. Konstruieren Sie ein 95 %-Konfidenzintervall für den allgemeinen Mittelwert dieser Verteilung. Berechnen Sie den Variationskoeffizienten (25 Punkte).
6. Der Gesamtstickstoffgehalt im Blutplasma von Albino-Ratten im Alter von 37 und 180 Tagen wurde untersucht. Die Ergebnisse werden in Gramm pro 100 cm 3 Plasma ausgedrückt. Im Alter von 37 Tagen hatten 9 Ratten: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Im Alter von 180 Tagen hatten 8 Ratten: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Legen Sie Konfidenzintervalle für die Differenz auf ein Konfidenzniveau von 0,95 (50 Punkte) fest.
7. Bestimmen Sie die Grenzen des 95 %-Konfidenzintervalls für die allgemeine Varianz der Verteilung von Kalzium (mg %) im Blutserum von Affen. Wenn für diese Verteilung die Stichprobengröße n = 100 beträgt, ist der statistische Fehler der Stichprobenvarianz S σ 2 = 1,60 (40 Punkte).
8. Bestimmen Sie die Grenzen des 95 %-Konfidenzintervalls für die allgemeine Varianz der Verteilung von 40 Weizenährchen entlang der Länge (σ 2 = 40,87 mm 2). (25 Punkte).
9. Rauchen gilt als Hauptprädispositionsfaktor für obstruktive Lungenerkrankungen. Passivrauchen gilt nicht als solcher Faktor. Wissenschaftler bezweifelten die Unbedenklichkeit des Passivrauchens und untersuchten die Durchgängigkeit der Atemwege von Nichtrauchern, Passiv- und Aktivrauchern. Um den Zustand der Atemwege zu charakterisieren, haben wir einen der Indikatoren der externen Atmungsfunktion herangezogen – den maximalen Volumenstrom in der Mitte der Ausatmung. Ein Rückgang dieses Indikators ist ein Zeichen für eine Atemwegsobstruktion. Die Umfragedaten sind in der Tabelle dargestellt.
|
Anzahl der untersuchten Personen |
Maximale Flussrate in der Mitte der Ausatmung, l/s |
||
|
Standardabweichung |
|||
|
Nichtraucher |
|||
|
in einem Nichtraucherbereich arbeiten | |||
|
Arbeiten in einem verrauchten Raum | |||
|
Rauchen |
|||
|
rauchen Sie eine kleine Anzahl Zigaretten | |||
|
durchschnittliche Anzahl der Zigarettenraucher | |||
|
eine große Anzahl Zigaretten rauchen | |||
Ermitteln Sie anhand der Tabellendaten 95 %-Konfidenzintervalle für den Gesamtmittelwert und die Gesamtvarianz für jede Gruppe. Was sind die Unterschiede zwischen den Gruppen? Stellen Sie die Ergebnisse grafisch dar (25 Punkte).
10. Bestimmen Sie die Grenzen der 95 %- und 99 %-Konfidenzintervalle für die allgemeine Varianz der Ferkelzahl in 64 Abferkeln, wenn der statistische Fehler der Stichprobenvarianz besteht S σ 2 = 8,25 (30 Punkte).
11. Es ist bekannt, dass das Durchschnittsgewicht von Kaninchen 2,1 kg beträgt. Bestimmen Sie die Grenzen der 95 %- und 99 %-Konfidenzintervalle für den allgemeinen Mittelwert und die Varianz bei N= 30, σ = 0,56 kg (25 Punkte).
12. Der Korngehalt der Ähre wurde für 100 Ähren gemessen ( X), Ohrlänge ( Y) und die Getreidemasse in der Ähre ( Z). Finden Sie Konfidenzintervalle für den allgemeinen Mittelwert und die Varianz unter P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 wenn
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064. (25 Punkte).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064. (25 Punkte).
13. In 100 zufällig ausgewählten Winterweizenähren wurde die Anzahl der Ährchen gezählt. Die Stichprobenpopulation wurde durch folgende Indikatoren charakterisiert:
 = 15 Ährchen und σ = 2,28 Stk. Bestimmen Sie, mit welcher Genauigkeit das Durchschnittsergebnis erhalten wurde (
= 15 Ährchen und σ = 2,28 Stk. Bestimmen Sie, mit welcher Genauigkeit das Durchschnittsergebnis erhalten wurde (  ) und erstellen Sie ein Konfidenzintervall für den allgemeinen Mittelwert und die Varianz auf den Signifikanzniveaus 95 % und 99 % (30 Punkte).
) und erstellen Sie ein Konfidenzintervall für den allgemeinen Mittelwert und die Varianz auf den Signifikanzniveaus 95 % und 99 % (30 Punkte).
14. Anzahl der Rippen auf fossilen Molluskenschalen Orthamboniten Kalligramm:
Es ist bekannt, dass N = 19, σ = 4,25. Bestimmen Sie die Grenzen des Konfidenzintervalls für den allgemeinen Mittelwert und die allgemeine Varianz auf dem Signifikanzniveau W = 0,01 (25 Punkte).
15. Zur Bestimmung der Milchleistung auf einem kommerziellen Milchviehbetrieb wurde täglich die Produktivität von 15 Kühen bestimmt. Nach Angaben des Jahres gab jede Kuh im Durchschnitt folgende Milchmenge pro Tag (l): 22; 19; 25; 20; 27; 17; dreißig; 21; 18; 24; 26; 23; 25; 20; 24. Konfidenzintervalle für die allgemeine Varianz und das arithmetische Mittel konstruieren. Können wir mit einer durchschnittlichen jährlichen Milchleistung von 10.000 Litern pro Kuh rechnen? (50 Punkte).
16. Um den durchschnittlichen Weizenertrag für den landwirtschaftlichen Betrieb zu ermitteln, wurden Versuchsparzellen von 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 und 2 Hektar gemäht. Die Produktivität (c/ha) der Parzellen betrug 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 bzw. Konstruieren Sie Konfidenzintervalle für die allgemeine Varianz und das arithmetische Mittel. Können wir davon ausgehen, dass der durchschnittliche landwirtschaftliche Ertrag 42 c/ha beträgt? (50 Punkte).