Gleichmäßige Verteilung entlang des Segments. Einheitliche Wahrscheinlichkeitsverteilung
Die Verteilungsfunktion hat in diesem Fall nach (5.7) die Form:
wobei: m – mathematische Erwartung, s – Standardabweichung.
Die Normalverteilung wird nach dem deutschen Mathematiker Gauß auch Gauß-Verteilung genannt. Die Tatsache, dass eine Zufallsvariable eine Normalverteilung mit Parametern hat: m, wird wie folgt bezeichnet: N (m,s), wobei: m =a =M ;
Sehr oft wird in Formeln der mathematische Erwartungswert mit bezeichnet A . Wenn eine Zufallsvariable nach dem Gesetz N(0,1) verteilt ist, dann nennt man sie eine normalisierte oder standardisierte Normalvariable. Die Verteilungsfunktion dafür hat die Form:
|
|
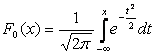 .
.Der Dichtegraph einer Normalverteilung, der als Normalkurve oder Gaußkurve bezeichnet wird, ist in Abb. 5.4 dargestellt.

Reis. 5.4. Normalverteilungsdichte
Anhand eines Beispiels wird die Bestimmung der numerischen Eigenschaften einer Zufallsvariablen anhand ihrer Dichte betrachtet.
Beispiel 6.
Eine kontinuierliche Zufallsvariable wird durch die Verteilungsdichte angegeben: ![]() .
.
Bestimmen Sie die Art der Verteilung, ermitteln Sie den mathematischen Erwartungswert M(X) und die Varianz D(X).
Wenn wir die gegebene Verteilungsdichte mit (5.16) vergleichen, können wir schließen, dass das Normalverteilungsgesetz mit m = 4 gegeben ist. Daher ist der mathematische Erwartungswert M(X)=4, die Varianz D(X)=9.
Standardabweichung s=3.
Die Laplace-Funktion, die die Form hat:
|
|
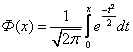 ,
,hängt mit der Normalverteilungsfunktion (5.17) zusammen, die Beziehung:
F 0 (x) = Ф(x) + 0,5.
Die Laplace-Funktion ist ungerade.
Ф(-x)=-Ф(x).
Die Werte der Laplace-Funktion Ф(х) werden tabellarisch aufgeführt und entsprechend dem Wert von x aus der Tabelle entnommen (siehe Anhang 1).
Die Normalverteilung einer kontinuierlichen Zufallsvariablen spielt in der Wahrscheinlichkeitstheorie eine wichtige Rolle und ist bei zufälligen Naturphänomenen sehr verbreitet. In der Praxis stoßen wir sehr häufig auf Zufallsvariablen, die gerade durch die Summation vieler Zufallsterme entstehen. Insbesondere die Analyse der Messfehler zeigt, dass es sich dabei um die Summe verschiedener Fehlerarten handelt. Die Praxis zeigt, dass die Wahrscheinlichkeitsverteilung von Messfehlern nahe am Normalgesetz liegt.
Mit der Laplace-Funktion können Sie das Problem der Berechnung der Wahrscheinlichkeit lösen, in ein bestimmtes Intervall und eine gegebene Abweichung einer normalen Zufallsvariablen zu fallen.
Wie bereits erwähnt, Beispiele für Wahrscheinlichkeitsverteilungen kontinuierliche Zufallsvariable X sind:
- gleichmäßige Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen;
- exponentielle Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen;
- Normalverteilung Wahrscheinlichkeiten einer kontinuierlichen Zufallsvariablen.
Geben wir das Konzept der gleichmäßigen und exponentiellen Verteilungsgesetze, Wahrscheinlichkeitsformeln und numerischen Eigenschaften der betrachteten Funktionen.
| Indikator | Einheitliches Vertriebsrecht | Exponentielles Verteilungsgesetz |
|---|---|---|
| Definition | Uniform genannt Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen X, deren Dichte auf dem Segment konstant bleibt und die Form hat | Exponential heißt Wahrscheinlichkeitsverteilung einer kontinuierlichen Zufallsvariablen X, die durch eine Dichte der Form beschrieben wird |
 wobei λ ein konstanter positiver Wert ist |
||
| Verteilungsfunktion |  |
|
| Wahrscheinlichkeit in das Intervall fallen |  |
|
| Erwartung | ||
| Streuung |  |
|
| Standardabweichung |  |
Beispiele zur Lösung von Problemen zum Thema „Gleich- und Exponentialverteilungsgesetze“
Aufgabe 1.
Die Busse fahren streng nach Fahrplan. Bewegungsintervall 7 Min. Finden Sie: a) die Wahrscheinlichkeit, dass ein an einer Haltestelle ankommender Fahrgast weniger als zwei Minuten auf den nächsten Bus wartet; b) die Wahrscheinlichkeit, dass ein an einer Haltestelle ankommender Fahrgast mindestens drei Minuten auf den nächsten Bus wartet; c) mathematischer Erwartungswert und Standardabweichung der Zufallsvariablen X – Passagierwartezeit.
Lösung. 1. Gemäß den Bedingungen des Problems eine kontinuierliche Zufallsvariable X = (Wartezeit der Passagiere) gleichmäßig verteilt zwischen der Ankunft zweier Busse. Die Länge des Verteilungsintervalls der Zufallsvariablen X ist gleich b-a=7, wobei a=0, b=7.
2. Die Wartezeit beträgt weniger als zwei Minuten, wenn die Zufallsvariable X in das Intervall (5;7) fällt. Wir ermitteln die Wahrscheinlichkeit, in ein bestimmtes Intervall zu fallen, mithilfe der Formel:<Х<х 2)=(х 2 -х 1)/(b-a)
.
P(x 1< Х < 7) = (7-5)/(7-0) = 2/7 ≈ 0,286.
P(5 Wir ermitteln die Wahrscheinlichkeit, in ein bestimmtes Intervall zu fallen, mithilfe der Formel:<Х<х 2)=(х 2 -х 1)/(b-a)
.
3. Die Wartezeit beträgt mindestens drei Minuten (also von drei bis sieben Minuten), wenn die Zufallsvariable X in das Intervall (0;4) fällt. Wir ermitteln die Wahrscheinlichkeit, in ein bestimmtes Intervall zu fallen, mithilfe der Formel:< Х < 4) = (4-0)/(7-0) = 4/7 ≈ 0,571.
P(0 4. Der mathematische Erwartungswert einer kontinuierlichen, gleichmäßig verteilten Zufallsvariablen X – die Wartezeit des Passagiers – wird mithilfe der Formel ermittelt: M(X)=(a+b)/2
. M(X) = (0+7)/2 = 7/2 = 3,5. 5. Die Standardabweichung einer kontinuierlichen, gleichmäßig verteilten Zufallsvariablen X – die Wartezeit des Passagiers – wird mit der Formel ermittelt:σ(X)=√D=(b-a)/2√3
. σ(X)=(7-0)/2√3=7/2√3≈2,02.
Die Exponentialverteilung ist für x ≥ 0 durch die Dichte f(x) = 5e – 5x gegeben. Erforderlich: a) Schreiben Sie einen Ausdruck für die Verteilungsfunktion auf; b) Finden Sie die Wahrscheinlichkeit, dass X als Ergebnis des Tests in das Intervall (1;4) fällt; c) Finden Sie die Wahrscheinlichkeit, dass als Ergebnis des Tests X ≥ 2 ist; d) Berechnen Sie M(X), D(X), σ(X).
Lösung. 1. Da die Bedingung gegeben ist Exponentialverteilung , dann erhalten wir aus der Formel für die Wahrder Zufallsvariablen X λ = 5. Dann hat die Verteilungsfunktion die Form:
2. Die Wahrscheinlichkeit, dass X als Ergebnis des Tests in das Intervall (1;4) fällt, wird durch die Formel ermittelt:
P(a< X < b) = e −λa − e −λb
.
P(1< X < 4) = e −5*1 − e −5*4 = e −5 − e −20 .
3. Die Wahrscheinlichkeit, dass als Ergebnis des Tests X ≥ 2 gefunden wird, nach der Formel: P(a< X < b) = e −λa − e −λb при a=2, b=∞.
P(X≥2) = P(1< X < 4) = e −λ*2 − e −λ*∞ = e −2λ − e −∞ =
e −2λ - 0 = e −10 (т.к. предел e −х при х стремящемся к ∞ равен нулю).
4. Finden Sie für die Exponentialverteilung:
- mathematischer Erwartungswert nach der Formel M(X) = 1/λ = 1/5 = 0,2;
- Varianz nach der Formel D(X) = 1/ λ 2 = 1/25 = 0,04;
- Standardabweichung nach der Formel σ(X) = 1/λ = 1/5 = 1,2.
Mit dessen Hilfe werden viele reale Prozesse simuliert. Und das häufigste Beispiel ist der Fahrplan der öffentlichen Verkehrsmittel. Angenommen, ein bestimmter Bus (Trolleybus/Straßenbahn) fährt alle 10 Minuten und Sie kommen zu einem zufälligen Zeitpunkt zum Stehen. Wie hoch ist die Wahrscheinlichkeit, dass der Bus innerhalb einer Minute ankommt? Offensichtlich 1/10. Wie groß ist die Wahrscheinlichkeit, dass Sie 4-5 Minuten warten müssen? Dasselbe . Wie groß ist die Wahrscheinlichkeit, dass Sie länger als 9 Minuten auf einen Bus warten müssen? Ein Zehntel!
Betrachten wir einige davon endlich Intervall, der Bestimmtheit halber soll es ein Segment sein. Wenn Zufallsvariable hat Konstante Wahrscheinlichkeitsverteilungsdichte auf einem bestimmten Segment und einer Dichte von Null außerhalb davon, dann sagt man, dass es verteilt ist gleichmäßig. In diesem Fall wird die Dichtefunktion streng definiert: 
In der Tat, wenn die Länge des Segments (siehe Zeichnung) ist, dann ist der Wert zwangsläufig gleich – so dass die Einheitsfläche des Rechtecks erhalten und beobachtet wird bekanntes Eigentum:
Lassen Sie es uns formal überprüfen:
, usw. Aus probabilistischer Sicht bedeutet dies, dass die Zufallsvariable zuverlässig werde einen der Werte des Segments annehmen..., eh, ich werde langsam ein langweiliger alter Mann =)
Das Wesen der Einheitlichkeit besteht darin, dass es keine innere Lücke gibt feste Länge wir haben nicht darüber nachgedacht (Denken Sie an die „Bus“-Minuten)– Die Wahrscheinlichkeit, dass eine Zufallsvariable einen Wert aus diesem Intervall annimmt, ist gleich. In der Zeichnung habe ich drei solcher Wahrscheinlichkeiten schattiert – das betone ich noch einmal sie werden durch Bereiche bestimmt, keine Funktionswerte!
Betrachten wir eine typische Aufgabe:
Beispiel 1
Eine kontinuierliche Zufallsvariable wird durch ihre Verteilungsdichte angegeben: ![]()
Finden Sie die Konstante, berechnen Sie die Verteilungsfunktion und stellen Sie sie zusammen. Erstellen Sie Diagramme. Finden
Mit anderen Worten, alles, wovon Sie träumen können :)
Lösung: seit in der Pause (endliches Intervall) ![]() , dann hat die Zufallsvariable eine gleichmäßige Verteilung und der Wert von „ce“ kann mithilfe der direkten Formel ermittelt werden
, dann hat die Zufallsvariable eine gleichmäßige Verteilung und der Wert von „ce“ kann mithilfe der direkten Formel ermittelt werden ![]() . Aber im Allgemeinen ist es besser – eine Eigenschaft zu verwenden:
. Aber im Allgemeinen ist es besser – eine Eigenschaft zu verwenden:
...warum ist es besser? Damit es keine unnötigen Fragen gibt ;)
Die Dichtefunktion lautet also: 
Machen wir die Zeichnung. Werte unmöglich
, und deshalb werden unten fette Punkte platziert: 
Berechnen wir zur schnellen Kontrolle die Fläche des Rechtecks: ![]() , usw.
, usw.
Finden wir mathematische Erwartung, und Sie können wahrscheinlich schon erraten, was es bedeutet. Denken Sie an den „10-Minuten“-Bus: Wenn zufällig Dann nähere ich mich der Haltestelle für viele, viele Tage durchschnittlich Sie müssen 5 Minuten auf ihn warten.
Ja, das stimmt – die Erwartung sollte genau in der Mitte des „Ereignis“-Intervalls liegen:
, wie erwartet.
Berechnen wir die Varianz mit Formel ![]() . Und hier braucht man bei der Integralberechnung ein Auge und ein Auge:
. Und hier braucht man bei der Integralberechnung ein Auge und ein Auge:
Daher, Streuung: ![]()
Lasst uns komponieren Verteilungsfunktion ![]() . Hier gibt es nichts Neues:
. Hier gibt es nichts Neues:
1) wenn, dann und ![]() ;
;
2) wenn , dann und:
3) und schließlich wann ![]() , Deshalb:
, Deshalb:
Infolge: 
Machen wir die Zeichnung: 
Im „Live“-Intervall die Verteilungsfunktion Anbau linear, und dies ist ein weiteres Zeichen dafür, dass wir eine gleichmäßig verteilte Zufallsvariable haben. Nun ja, natürlich, schließlich Derivat lineare Funktion- Es gibt eine Konstante.
Die erforderliche Wahrscheinlichkeit kann mithilfe der gefundenen Verteilungsfunktion auf zwei Arten berechnet werden:
oder unter Verwendung eines bestimmten Dichteintegrals: 
Wem es gefällt.
Und hier können Sie auch schreiben Antwort: , , die Graphen werden entlang der Lösung aufgebaut.
, die Graphen werden entlang der Lösung aufgebaut.
... „es ist möglich“, denn sein Fehlen wird in der Regel nicht bestraft. Normalerweise;)
Für die Berechnung einer einheitlichen Zufallsvariablen gibt es spezielle Formeln, die Sie am besten selbst ableiten:
Beispiel 2
Eine kontinuierliche Zufallsvariable ist durch die Dichte gegeben  .
.
Berechnen Sie den mathematischen Erwartungswert und die Varianz. Vereinfachen Sie die Ergebnisse so weit wie möglich (abgekürzte Multiplikationsformeln helfen).
Die resultierenden Formeln eignen sich zur Überprüfung. Überprüfen Sie insbesondere das gerade gelöste Problem, indem Sie bestimmte Werte von „a“ und „b“ einsetzen. Kurze Lösung unten auf der Seite.
Und am Ende der Lektion werden wir uns ein paar „Text“-Probleme ansehen:
Beispiel 3
Der Skalenteilungswert des Messgerätes beträgt 0,2. Die Instrumentenwerte werden auf die nächste ganze Division gerundet. Unter der Annahme, dass die Rundungsfehler gleichmäßig verteilt sind, ermitteln Sie die Wahrscheinlichkeit, dass sie bei der nächsten Messung 0,04 nicht überschreitet.
Zum besseren Verständnis Lösungen Stellen wir uns vor, dass es sich um eine Art mechanisches Gerät mit einem Pfeil handelt, zum Beispiel eine Waage mit einem Teilwert von 0,2 kg, und wir müssen die Katze im Sack wiegen. Aber nicht, um seine Fettigkeit herauszufinden – jetzt kommt es darauf an, WO der Pfeil zwischen zwei benachbarten Teilungen stoppt.
Betrachten wir eine Zufallsvariable - Distanz Pfeile aus nächste linke Abteilung. Oder vom nächsten rechts, das spielt keine Rolle.
Lassen Sie uns die Wzusammenstellen:
1) Da der Abstand nicht negativ sein kann, dann auf dem Intervall . Logisch.
2) Aus der Bedingung folgt, dass der Pfeil der Waage mit gleiche Wahrscheinlichkeit kann überall zwischen den Divisionen anhalten *
, einschließlich der Divisionen selbst, und daher auf dem Intervall: ![]()
* Dies ist eine wesentliche Voraussetzung. So bleibt beispielsweise beim Abwiegen von Wattestücken oder Kilogramm-Salzpackungen die Gleichmäßigkeit über deutlich engere Intervalle erhalten.
3) Und da der Abstand von der NÄCHSTEN linken Teilung nicht größer als 0,2 sein kann, ist at auch gleich Null.
Daher: 
Es sei darauf hingewiesen, dass uns niemand nach der Dichtefunktion gefragt hat und ich ihre vollständige Konstruktion ausschließlich in kognitiven Ketten dargestellt habe. Am Ende der Aufgabe genügt es, nur den 2. Punkt aufzuschreiben.
Beantworten wir nun die Frage nach dem Problem. Wann wird der Fehler beim Runden auf die nächste Teilung 0,04 nicht überschreiten? Dies geschieht, wenn der Pfeil nicht weiter als 0,04 von der linken Teilung entfernt stoppt Rechts oder nicht weiter als 0,04 von der rechten Teilung entfernt links. In der Zeichnung habe ich die entsprechenden Bereiche schattiert: 
Diese Bereiche müssen noch gefunden werden Integrale verwenden. Im Prinzip kann man sie „schulmäßig“ berechnen (wie die Flächen von Rechtecken), aber die Einfachheit ist nicht immer verstanden ;)
Von der Satz der Addition von Wahrscheinlichkeiten inkompatibler Ereignisse:
– die Wahrscheinlichkeit, dass der Rundungsfehler 0,04 nicht überschreitet (in unserem Beispiel 40 Gramm)
Es ist leicht zu erkennen, dass der maximal mögliche Rundungsfehler 0,1 (100 Gramm) beträgt und daher Wahrscheinlichkeit, dass der Rundungsfehler 0,1 nicht überschreitet gleich eins.
Antwort: 0,4
Es gibt alternative Erklärungen/Formulierungen zu diesem Problem in anderen Informationsquellen, und ich habe die Option gewählt, die mir am verständlichsten erschien. Besondere Aufmerksamkeit Es ist darauf zu achten, dass es sich bei der Bedingung um Fehler handeln kann, NICHT um Rundungen, sondern um Fehler zufällig Messfehler, die normalerweise auftreten (aber nicht immer), verteilt durch normales Gesetz. Daher, Nur ein Wort kann Ihre Entscheidung radikal ändern! Seien Sie wachsam und verstehen Sie die Bedeutung.
Und sobald sich alles im Kreis dreht, bringen uns unsere Füße zur selben Bushaltestelle:
Beispiel 4
Busse auf einer bestimmten Strecke verkehren streng nach Fahrplan und im 7-Minuten-Takt. Erstellen Sie eine Dichtefunktion einer Zufallsvariablen – der Wartezeit eines Passagiers auf den nächsten Bus, der sich zufällig der Haltestelle nähert. Ermitteln Sie die Wahrscheinlichkeit, dass er nicht länger als drei Minuten auf den Bus warten wird. Finden Sie die Verteilungsfunktion und erklären Sie ihre sinnvolle Bedeutung.
Als gleichmäßig gilt eine Verteilung, bei der alle Werte einer Zufallsvariablen (im Bereich ihrer Existenz, beispielsweise im Intervall) gleich wahrscheinlich sind. Die Verteilungsfunktion für eine solche Zufallsvariable hat die Form:
Verteilungsdichte: 
 1
1

Reis. Diagramme der Verteilungsfunktion (links) und der Verteilungsdichte (rechts).
Gleichmäßige Verteilung – Konzept und Typen. Einordnung und Merkmale der Kategorie „Gleichmäßige Verteilung“ 2017, 2018.
Grundlegende diskrete Verteilungen von Zufallsvariablen Definition 1. Eine Zufallsvariable X mit den Werten 1, 2, ..., n hat eine gleichmäßige Verteilung, wenn Pm = P(X = m) = 1/n, m = 1, ..., N.
Offensichtlich. Betrachten Sie das folgende Problem. Es gibt N Kugeln in der Urne, von denen M weiß sind... .
Gesetze der Verteilung kontinuierlicher Zufallsvariablen Definition 5. Eine kontinuierliche Zufallsvariable X, die einen Wert im Intervall annimmt, hat eine gleichmäßige Verteilung, wenn die Verteilungsdichte die Form hat. (1) Es ist leicht zu überprüfen, dass .
Wenn eine Zufallsvariable... .< b; a и b – это параметры равномерного закона. Найдем функцию распределения F(x)... .
Als gleichmäßig gilt eine Verteilung, bei der alle Werte einer Zufallsvariablen (im Bereich ihrer Existenz, beispielsweise im Intervall) gleich wahrscheinlich sind. Die Verteilungsfunktion für eine solche Zufallsvariable hat die Form: Verteilungsdichte: F(x) f(x) 1 0 a b x 0 a b x ... .
Definition 16. Eine kontinuierliche Zufallsvariable hat eine gleichmäßige Verteilung auf dem Segment, wenn die Verteilungsdichte dieser Zufallsvariablen auf diesem Segment konstant ist und außerhalb davon gleich Null ist, d. h. (45). Das Dichtediagramm für eine gleichmäßige Verteilung wird angezeigt...
Dieses Thema wird seit langem eingehend untersucht, und die am weitesten verbreitete Methode ist die Polarkoordinatenmethode, die 1958 von George Box, Mervyn Muller und George Marsaglia vorgeschlagen wurde. Mit dieser Methode können Sie ein Paar unabhängiger normalverteilter Zufallsvariablen mit dem mathematischen Erwartungswert 0 und der Varianz 1 wie folgt erhalten:
Wobei Z 0 und Z 1 die gewünschten Werte sind, s = u 2 + v 2 und u und v Zufallsvariablen sind, die gleichmäßig auf dem Intervall (-1, 1) verteilt sind und so ausgewählt werden, dass Bedingung 0 erfüllt ist< s < 1.
Viele Menschen verwenden diese Formeln, ohne darüber nachzudenken, und viele ahnen nicht einmal, dass sie existieren, da sie vorgefertigte Implementierungen verwenden. Aber es gibt Leute, die Fragen haben: „Woher kommt diese Formel?“ Und warum bekommt man gleich mehrere Mengen auf einmal?“ Als nächstes werde ich versuchen, eine klare Antwort auf diese Fragen zu geben.
Lassen Sie mich zunächst daran erinnern, was Wahrscheinlichkeitsdichte, Verteilungsfunktion einer Zufallsvariablen und Umkehrfunktion sind. Angenommen, es gibt eine bestimmte Zufallsvariable, deren Verteilung durch die Dichtefunktion f(x) angegeben wird, die die folgende Form hat:

Dies bedeutet, dass die Wahrscheinlichkeit, dass der Wert einer bestimmten Zufallsvariablen im Intervall (A, B) liegt, gleich der Fläche des schattierten Bereichs ist. Und als Konsequenz muss die Fläche der gesamten schattierten Fläche gleich eins sein, da der Wert der Zufallsvariablen in jedem Fall in den Definitionsbereich der Funktion f fällt.
Die Verteilungsfunktion einer Zufallsvariablen ist das Integral der Dichtefunktion. Und in diesem Fall sieht das ungefähre Erscheinungsbild so aus:

Die Bedeutung hier ist, dass der Wert der Zufallsvariablen mit der Wahrscheinlichkeit B kleiner als A sein wird. Infolgedessen nimmt die Funktion nie ab und ihre Werte liegen im Intervall.
Eine Umkehrfunktion ist eine Funktion, die ein Argument an die Originalfunktion zurückgibt, wenn ihr der Wert der Originalfunktion übergeben wird. Beispielsweise ist für die Funktion x 2 die Umkehrfunktion die Wurzelextraktionsfunktion, für sin(x) ist sie arcsin(x) usw.
Da die meisten Pseudozufallszahlengeneratoren nur eine Gleichverteilung als Ausgabe erzeugen, besteht häufig die Notwendigkeit, diese in eine andere umzuwandeln. In diesem Fall zur normalen Gaußschen Funktion:

Die Grundlage aller Methoden zur Umwandlung einer Gleichverteilung in eine andere ist die Methode der Rücktransformation. Es funktioniert wie folgt. Es wird eine Funktion gefunden, die zur Funktion der erforderlichen Verteilung invers ist, und ihr wird als Argument eine gleichmäßig über das Intervall (0, 1) verteilte Zufallsvariable übergeben. Am Ausgang erhalten wir einen Wert mit der erforderlichen Verteilung. Zur Verdeutlichung stelle ich das folgende Bild zur Verfügung.

Somit wird ein gleichmäßiges Segment entsprechend der neuen Verteilung sozusagen verschmiert und durch eine Umkehrfunktion auf eine andere Achse projiziert. Das Problem besteht jedoch darin, dass das Integral der Dichte einer Gaußschen Verteilung nicht einfach zu berechnen ist, sodass die oben genannten Wissenschaftler schummeln mussten.
Es gibt eine Chi-Quadrat-Verteilung (Pearson-Verteilung), die die Verteilung der Summe der Quadrate von k unabhängigen normalen Zufallsvariablen ist. Und im Fall k = 2 ist diese Verteilung exponentiell.

Das heißt, wenn ein Punkt in einem rechteckigen Koordinatensystem zufällige X- und Y-Koordinaten normalverteilt hat, dann wird nach der Konvertierung dieser Koordinaten in das Polarsystem (r, θ) das Quadrat des Radius (der Abstand vom Ursprung zum Punkt) berechnet. wird nach dem Exponentialgesetz verteilt, da das Quadrat des Radius die Summe der Quadrate der Koordinaten ist (nach dem pythagoräischen Gesetz). Die Verteilungsdichte solcher Punkte auf der Ebene sieht folgendermaßen aus:


Da er in alle Richtungen gleich ist, weist der Winkel θ eine gleichmäßige Verteilung im Bereich von 0 bis 2π auf. Das Umgekehrte gilt auch: Wenn Sie einen Punkt im Polarkoordinatensystem mithilfe zweier unabhängiger Zufallsvariablen (einem gleichmäßig verteilten Winkel und einem exponentiell verteilten Radius) definieren, sind die rechtwinkligen Koordinaten dieses Punktes unabhängige normale Zufallsvariablen. Und es ist viel einfacher, aus einer gleichmäßigen Verteilung mit derselben inversen Transformationsmethode eine Exponentialverteilung zu erhalten. Dies ist die Essenz der polaren Box-Muller-Methode.
Lassen Sie uns nun die Formeln ableiten.
![]() (1)
(1)
Um r und θ zu erhalten, müssen wir zwei gleichmäßig über das Intervall (0, 1) verteilte Zufallsvariablen generieren (nennen wir sie u und v), von denen die Verteilung einer davon (sagen wir v) in eine Exponentialverteilung umgewandelt werden muss Ermitteln Sie den Radius. Die Exponentialverteilungsfunktion sieht folgendermaßen aus:
Seine Umkehrfunktion ist:
![]()
Da die Gleichverteilung symmetrisch ist, funktioniert die Transformation mit der Funktion ähnlich
![]()
Aus der Chi-Quadrat-Verteilungsformel folgt, dass λ = 0,5. Setze λ, v in diese Funktion ein und erhalte das Quadrat des Radius und dann den Radius selbst:

Wir erhalten den Winkel, indem wir das Einheitssegment auf 2π strecken:
Jetzt setzen wir r und θ in die Formeln (1) ein und erhalten:
 (2)
(2)
Diese Formeln sind bereits gebrauchsfertig. X und Y sind unabhängig und normalverteilt mit einer Varianz von 1 und einem mathematischen Erwartungswert von 0. Um eine Verteilung mit anderen Merkmalen zu erhalten, reicht es aus, das Ergebnis der Funktion mit der Standardabweichung zu multiplizieren und den mathematischen Erwartungswert zu addieren.
Es ist jedoch möglich, trigonometrische Funktionen loszuwerden, indem man den Winkel nicht direkt, sondern indirekt über die rechtwinkligen Koordinaten eines zufälligen Punktes im Kreis angibt. Mithilfe dieser Koordinaten ist es dann möglich, die Länge des Radiusvektors zu berechnen und dann den Kosinus und den Sinus zu ermitteln, indem x bzw. y durch diese Koordinaten dividiert werden. Wie und warum funktioniert es?
Wählen wir einen zufälligen Punkt aus den gleichmäßig auf einem Kreis mit Einheitsradius verteilten Punkten aus und bezeichnen wir das Quadrat der Länge des Radiusvektors dieses Punktes mit dem Buchstaben s:

Die Auswahl erfolgt durch Angabe zufälliger rechtwinkliger Koordinaten x und y, die gleichmäßig im Intervall (-1, 1) verteilt sind, und durch Verwerfen von Punkten, die nicht zum Kreis gehören, sowie des Mittelpunkts, an dem der Winkel des Radiusvektors liegt ist nicht definiert. Das heißt, Bedingung 0 muss erfüllt sein< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Wir erhalten die Formeln wie am Anfang des Artikels. Der Nachteil dieser Methode besteht darin, dass Punkte verworfen werden, die nicht im Kreis enthalten sind. Das heißt, es werden nur 78,5 % der generierten Zufallsvariablen verwendet. Auf älteren Computern war das Fehlen trigonometrischer Funktionen noch ein großer Vorteil. Wenn nun ein Prozessorbefehl sowohl Sinus als auch Cosinus im Handumdrehen berechnet, können diese Methoden meiner Meinung nach immer noch mithalten.
Persönlich habe ich noch zwei Fragen:
- Warum ist der Wert von s gleichmäßig verteilt?
- Warum ist die Summe der Quadrate zweier normaler Zufallsvariablen exponentiell verteilt?

Wenn eine ähnliche Transformation für eine normale Zufallsvariable durchgeführt wird, ähnelt die Dichtefunktion ihres Quadrats einer Hyperbel. Und die Addition zweier Quadrate normaler Zufallsvariablen ist ein viel komplexerer Prozess, der mit der doppelten Integration verbunden ist. Und die Tatsache, dass das Ergebnis eine Exponentialverteilung sein wird, muss für mich persönlich noch durch eine praktische Methode überprüft oder als Axiom akzeptiert werden. Und allen Interessierten empfehle ich, sich näher mit dem Thema auseinanderzusetzen und Erkenntnisse aus diesen Büchern zu gewinnen:
- Ventzel E.S. Wahrscheinlichkeitstheorie
- Knut D.E. Die Kunst des Programmierens, Band 2
Abschließend ist hier ein Beispiel für die Implementierung eines normalverteilten Zufallszahlengenerators in JavaScript:
Funktion Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefiniert ? 0.0: mittelwert; dev = dev == undefiniert ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1.0; s = u * u + v * v; while (s > 1.0 || s == 0.0); return r * v * dev + Mittelwert ) ) g = new Gauss(); // ein Objekt erstellen a = g.next(); // ein Wertepaar generieren und den ersten erhalten b = g.next(); // Holen Sie sich das zweite c = g.next(); // Erzeuge erneut ein Wertepaar und erhalte das erste
Die Parameter Mittelwert (mathematischer Erwartungswert) und Dev (Standardabweichung) sind optional. Ich mache Sie darauf aufmerksam, dass der Logarithmus natürlich ist.



