Изчисляване на размера на извадката. Формула за вземане на проби - проста
| Име на параметъра | Значение |
| Тема на статията: | Тема 5: Примерно изчисление |
| Рубрика (тематична категория) | Маркетинг |
Често размерът на изследваната съвкупност е голям или е изключително времеемко и скъпо да се получи информация от цялата популация. В тези случаи се формира и изследва извадкова съвкупност. Но трябва да се помни, че получените данни винаги съдържат грешка; резултатите от наблюдението могат да бъдат оценени само с известна степен на надеждност.
Население- ϶ᴛᴏ съвкупността от всички единици, които са обект на изследване, от които се прави селекция.
Извадкова популация– съвкупността от единици, избрани за изследването.
Методи за конструиране на извадка:
1. Проста случайна извадка - всеки елемент от популацията има еднаква вероятност да бъде включен в извадката. Произвежда се с помощта на генератор на произволни числа;
2. Систематичен - първият елемент от извадковата съвкупност се избира случайно, след което всеки i-ти елемент се включва в извадковата съвкупност;
3. Стратифицирани (структурирани) - генералната съвкупност се разделя на няколко страти (групи), след което чрез прост случаен или систематичен извадков метод се прави подбор във всяка от групите;
4. Клъстерна извадка - генералната съвкупност се разделя на клъстери, след което чрез произволна извадка се избират няколко клъстера и се изследват всички обекти от избраните клъстери.
Методи за избор:
1. Повторно вземане на проби - една или друга единица, включена в извадката след регистрация, се връща в генералната съвкупност и запазва равна възможност с всички останали единици да попадне отново в извадката при повторно вземане на проби. Общият брой единици в популацията остава непроменен по време на процеса на вземане на проби.
2. Неповтаряща се извадка - единица от съвкупността, включена в извадката, не се връща в генералната съвкупност и не участва в по-нататъшен подбор. Общият брой единици в популацията се намалява по време на процеса на вземане на проби.
Подходи за определяне на размера на извадката:
1. Произволност – без доказателства се приема извадката да е 5–10% от генералната съвкупност. Този подход е лесен за използване, но не е възможно да се определи точността на получените резултати. При достатъчно голямо население би трябвало да е доста скъпо.
2. Въз основа на предишен опит – обхватът трябва да бъде установен от предишни проведени проучвания. Подходът има определена логика, при условие че предишната извадка е определена правилно.
3. Фокусирайте се върху разходите за провеждане – бюджетът за маркетингови проучвания предвижда разходи за провеждане на проучвания, които не могат да бъдат надвишавани. Точността на получената информация не е гарантирана и може да възникне свръхсемплиране.
4. Статистически методи – грешки възникват при всяко извадково изследване. За изчисляване на размера на извадката са посочени две стойности:
- Доверителният интервал (допустима грешка на извадката (∆)) е определена стойност, с която общите резултати могат да се различават от резултатите от извадката. Това е допустимото отклонение на наблюдаваните стойности от истинските изследователят отчита изискванията за точност на информацията.
- Доверителна вероятност - означава степента на увереност, че стойността на наблюдавания елемент ще попадне в определения диапазон на доверителния интервал. Най-често се използва нивото на сигурност от 95%.
Най-честите вероятности при провеждане на изследвания:
Дисперсия на извадката (вариация на характеристика в извадкова съвкупност):
![]()
N е броят на единиците в генералната съвкупност.
В този случай се взема според предишното проучване или се изчислява:
Ако са известни най-големите и най-малките стойности на характеристика в популацията:
![]() ;
;
http://www.quans.ru/research/control/select-calc/
Извадката от съвкупността трябва да бъде представителна, т.е. да осигурява пропорционално представяне на основните характеристики на популацията в извадката.
Представителността може да се илюстрира със следния пример. Да предположим, че населението е всички ученици на училището (600 души от 20 класа, по 30 души във всеки клас). Обект на изследване е отношението към тютюнопушенето. Извадка, състояща се от 60 гимназисти, представя популацията много по-зле от извадка от същите 60 души, която ще включва по 3 ученици от всеки клас. Основната причина за това е неравномерното възрастово разпределение в класовете. Следователно в първия случай представителността на извадката е ниска, а във втория случай е висока (при равни други условия).
Когато се използва методът на наблюдение, човек трябва да се стреми да преодолее синдромите на Дракула и Франкенщайн. Първият е желанието да се „изсмуче“ цялата мислима и немислима информация от непредставителни наблюдения. Второто е в желанието да се използват необмислено количествени характеристики. Пътят към успеха е внимателното използване както на количествени, така и на качествени методи; Провеждане както на широкомащабни проучвания, така и на наблюдения в малки групи.
Основната пречка за правенето на ефективни прогнози с помощта на метода на проучването е известният парадокс на Ла Пиер, който гласи, че хората не винаги действат така, както казват.
Тема 5: Извадково изчисляване - понятие и видове. Класификация и особености на категория "Тема 5: Примерно изчисление" 2017, 2018г.
Интервална оценка на вероятността за събитие. Формули за изчисляване на размера на извадката, като се използва метод на чисто случайна извадка.За да определим вероятностите за събития, които ни интересуват, ние използваме метод на вземане на проби: ние провеждаме ннезависими експерименти, във всеки от които събитие А може да се случи (или да не се случи) (вероятност Рпоявата на събитие А във всеки експеримент е постоянна). Тогава относителната честота p* на възникване на събития Ав поредица от нтестове се приема като точкова оценка за вероятността стрнастъпване на събитие Ав отделен процес. В този случай се извиква стойността p* примерен дял събития на събитието Аи p - общи акции .
Поради следствието от централната гранична теорема (теорема на Moivre-Laplace), относителната честота на събитие с голям размер на извадката може да се счита за нормално разпределена с параметри M(p*)=p и
Следователно, за n>30, може да се конструира доверителен интервал за общия дял, като се използват формулите:

където u cr се намира от таблиците на функцията на Лаплас, като се вземе предвид дадената доверителна вероятност γ: 2Ф(u cr)=γ.
При малък размер на извадката n≤30, максималната грешка ε се определя от таблицата за разпределение на Student: ![]() където tcr =t(k; α) и броя на степените на свобода k=n-1 вероятност α=1-γ (двустранна област).
където tcr =t(k; α) и броя на степените на свобода k=n-1 вероятност α=1-γ (двустранна област).
Формулите са валидни, ако изборът е извършен по случаен, повторен начин (генералната съвкупност е безкрайна), в противен случай е необходимо да се направи корекция за неповтаряне на избора (таблица).
Средна извадкова грешка за общия дял
| Население | Безкраен | Краен обем н |
| Тип селекция | Повтаря се | Неповторими |
| Средна извадкова грешка |
Формули за изчисляване на размера на извадката, като се използва метод на чисто случайна извадка
| Метод на избор | Формули за определяне на размера на извадката | ||
| за средно | за споделяне | ||
| Повтаря се | |||
| Неповторими | |||
Общи проблеми с акциите
На въпроса „Интервалът на доверие покрива ли дадената стойност на p0?“ - може да се отговори чрез проверка на статистическата хипотеза H 0:p=p 0 . Предполага се, че експериментите се провеждат по схемата на теста на Бернули (независима, вероятност стрнастъпване на събитие Ае постоянен). По обемна проба нопределяне на относителната честота p * на възникване на събитие A: където м- брой появявания на събитието Ав поредица от нтестове. За проверка на хипотезата H 0 се използват статистики, които при достатъчно голям размер на извадката имат стандартно нормално разпределение (Таблица 1).Таблица 1 - Хипотези за общия дял
Хипотеза | H 0:p=p 0 | H 0:p 1 = p 2 |
| Предположения | Верига за изпитване на Бернули | Верига за изпитване на Бернули |
| Примерни оценки | 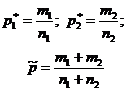 |
|
| Статистика К |  |  |
| Разпределение на статистиката К | Стандартно нормално N(0,1) |
Пример №1. Използвайки повторна случайна извадка, ръководството на фирмата проведе извадково проучване на 900 свои служители. Сред анкетираните има 270 жени. Конструирайте доверителен интервал с вероятност 0,95, покриващ реалния дял на жените в целия екип на компанията.
Решение. Съгласно условието извадковият дял на жените е (относителна честота на жените сред всички респонденти). Тъй като селекцията се повтаря и размерът на извадката е голям (n=900), максималната грешка на извадката се определя по формулата ![]()
Стойността на u cr се намира от таблицата на функцията на Лаплас от връзката 2Ф(u cr) = γ, т.е. ![]() Функцията на Лаплас (Приложение 1) приема стойност 0,475 при u cr =1,96. Следователно пределната грешка
Функцията на Лаплас (Приложение 1) приема стойност 0,475 при u cr =1,96. Следователно пределната грешка ![]() и желания доверителен интервал
и желания доверителен интервал
(p – ε, p + ε) = (0,3 – 0,18; 0,3 + 0,18) = (0,12; 0,48)
И така, с вероятност от 0,95 можем да гарантираме, че делът на жените в целия екип на компанията е в диапазона от 0,12 до 0,48.
Пример №2. Собственикът на паркинга счита деня за „щастлив“, ако паркингът е пълен над 80%. През годината са извършени 40 проверки на парка, от които 24 са „успешни”. С вероятност от 0,98 намерете доверителен интервал за оценка на истинския дял на „щастливите“ дни през годината.
Решение. Примерният дял на „щастливите“ дни е
Използвайки таблицата на функцията на Лаплас, намираме стойността на u cr за дадено
вероятност за доверие
Ф(2,23) = 0,49, ucr = 2,33.
Като се има предвид, че изборът е неповтарящ се (т.е. две проверки не са извършени в един и същи ден), ще открием ограничаващата грешка: ![]()
където n=40, N=365 (дни). Оттук ![]()
и доверителен интервал за общия дял: (p – ε, p + ε) = (0,6 – 0,17; 0,6 + 0,17) = (0,43; 0,77)
С вероятност от 0,98 можем да очакваме делът на „щастливите” дни през годината да бъде в диапазона от 0,43 до 0,77.
Пример №3. След като провериха 2500 продукта в партидата, те установиха, че 400 продукта са от най-висок клас, но n–m не са. Колко продукта трябва да бъдат проверени, за да се определи с 95% сигурност делът на най-високата оценка с точност 0,01?
Търсим решение, използвайки формулата за определяне на размера на извадката за повторна селекция.
Ф(t) = γ/2 = 0,95/2 = 0,475 и тази стойност според таблицата на Лаплас отговаря на t=1,96
Съотношение на пробата w = 0,16; грешка на извадката ε = 0,01
Пример №4. Партида от продукти се приема, ако вероятността продуктът да отговаря на стандарта е най-малко 0,97. Сред произволно избраните 200 продукта от тестваната партида, 193 отговарят на стандарта. Възможно ли е да се приеме партидата при ниво на значимост α=0,02?
Решение. Нека формулираме основната и алтернативните хипотези.
H 0:p=p 0 =0,97 - неизвестен общ дял стрравна на зададената стойност p 0 =0,97. Във връзка с условието - вероятността част от проверяваната партида да отговаря на стандарта е равна на 0,97; тези. Партидата продукти може да бъде приета.
H 1:p<0,97 - вероятность того, что деталь из проверяемой партии окажется соответствующей стандарту, меньше 0.97; т.е. партию изделий нельзя принять. При такой альтернативной гипотезе критическая область будет левосторонней.
Наблюдавана статистическа стойност К(таблица) изчислете за дадени стойности p 0 =0,97, n=200, m=193
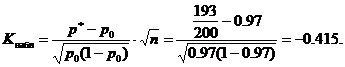
Намираме критичната стойност от таблицата на функцията на Лаплас от равенството
![]()
Съгласно условието α = 0,02, следователно F(Kcr) = 0,48 и Kcr = 2,05. Критичният регион е левостранен, т.е. е интервалът (-∞;-K kp)= (-∞;-2,05). Наблюдаваната стойност K obs = -0,415 не принадлежи към критичната област, следователно при това ниво на значимост няма причина да се отхвърли основната хипотеза. Можете да приемете партида от продукти.
Пример №5. Две фабрики произвеждат един и същи тип части. За оценка на качеството им са взети проби от продуктите на тези фабрики и са получени следните резултати. Сред 200 избрани продукта от първия завод 20 бяха дефектни, а сред 300 продукта от втория завод 15 бяха дефектни.
При ниво на значимост от 0,025 разберете дали има значителна разлика в качеството на частите, произведени от тези фабрики.
Съгласно условието α = 0,025, следователно F(Kcr) = 0,4875 и Kcr = 2,24. При двустранна алтернатива диапазонът от приемливи стойности има формата (-2,24; 2,24). Наблюдаваната стойност K obs =2,15 попада в този интервал, т.е. при това ниво на значимост няма причина да се отхвърли основната хипотеза. Фабриките произвеждат продукти с еднакво качество.
Всяка професия има свой набор от любими въпроси. За изследователите на пазара въпросът за размера на извадката е на първо място в този списък, разбира се. Обикновено се формулира така:
- Бихме искали да възложим проучване на посетителите на московските търговски центрове. Каква проба ни трябва?
- Нашата целева аудитория е приблизително 300 000 души. Колко хора трябва да анкетираме, за да сме представителни? Ами ако целевата аудитория е 3 милиона?
- Трябва да оценим потенциала за продажба на апартаменти в Санкт Петербург на жителите на северните руски градове. Каква проба да направя?
Основното погрешно схващане за размера на извадката
Много хора вярват, че колкото по-голяма е целевата група, толкова по-голям трябва да бъде размерът на извадката. Следователно, уж, за да разберете мнението на жителите на малък град, е достатъчно да интервюирате 200-300 души, но за да разберете мнението за Русия като цяло, 5000 няма да са достатъчни.
Междувременно този стереотип няма нищо общо с реалността. Размерът на извадката не зависи от размера на целевата група (на статистически език се нарича „генерална съвкупност“) и се определя от два напълно различни фактора. Единственото изключение от това правило са случаите, когато населението е много малко, например 1-2 хиляди души, но такива ситуации са рядкост в реалната практика на маркетингови проучвания.
Два фактора, които определят размера на извадката
Размерът на извадката при масово проучване зависи от два фактора:
- Точността на данните, които трябва да бъдат получени на изхода, е същата „статистическа грешка“. За извадка от 100 респондента тя ще бъде в рамките на плюс-минус 10%, а за извадка от 1000 респондента ще бъде в рамките на плюс-минус 3,1%. Повече подробности за това по-долу.
- Броят и размерът на подгрупите, на които пробата трябва да бъде разделена по време на анализа. Например, ако се провежда електорално проучване, тогава ще се интересуваме основно от ядрото на активните избиратели. По правило делът на „ядрото“ рядко надвишава 20-25% от общото население. Следователно размерът на извадката трябва да бъде изчислен така, че една четвърт от общия й обем да позволява пълен статистически анализ.
Два вида грешка при вземане на проби
Всяко селективно наблюдение (т.е. когато не интервюираме всички, а правим случаен подбор от общата популация) е свързано с грешка в данните. Тази грешка обикновено се нарича "грешка при вземане на проби". Може да бъде два вида:
- Систематичен– е свързано с грешки в дизайна на пробите. Оценяването на неговия размер, посока и степен на изместване е много трудно, най-често невъзможно. Например, ако на респондентите се задават въпроси от представители на маргинализирани социални класи, това ще повлияе на желанието за участие в изследването от страна на представители на по-заможни групи от населението. В резултат това ще доведе до изключително трудна за оценка систематична грешка и изкривяване на данните.
- Случаен– свързано е с действието на законите на статистиката. Размерът му се изчислява лесно с помощта на формулите на математическата статистика и теорията на вероятностите. Те ви позволяват да направите информирани заключения относно доверителния интервал на даден знак. Например, ако статистическата грешка е плюс или минус 10%, а получената стойност на индикатора се окаже 25%, тогава доверителният интервал е от 15% до 35%.

Целта на изследователя е да събира данни по начин, който минимизира пристрастията на извадката. Тогава ще бъде възможно да се намали статистическата грешка само до случайна грешка, която може да се изчисли с помощта на формули.
Как да изчислим размера на случайната грешка при вземане на проби
Случайната грешка на извадката зависи не само от размера на извадката, но и от дисперсията, тоест степента на хомогенност на данните. Колкото по-хомогенни са данните (т.е. колкото по-малко е разпространението на получените стойности или дисперсия), толкова по-малка е грешката на извадката.
Има формула за изчисляване на произволна извадкова грешка, но за удобство препоръчваме да използвате онлайн калкулатори, например този. Тя ви позволява лесно да извършвате два вида изчисления:
- изчисляване на размера на статистическата грешка въз основа на размера на извадката и изчислената дисперсия;
- определя размера на извадката, необходим за получаване на оценка на желаната степен на прецизност.

Параметърът за доверие (едно от полетата в калкулатора) обикновено е настроен на 95%. Това означава, че в 95% от случаите разпределението на характеристиката в популацията ще попадне в рамките на изчисления доверителен интервал (т.е. стойността на самата характеристика в извадката плюс или минус размера на статистическата грешка). По-рядко се използва стойност на надеждност от 97% или 99% - това съответно означава, че такова попадение ще се случи в 97% или 99% от случаите. В този случай надеждността на извадката се увеличава, но размерът на извадката се увеличава.
Най-трудната част от определянето на размера на извадката е компромисът между изискваната точност и разходите за събиране на данни. Този процес се усложнява от факта, че учетворяването на размера на извадката води само до удвояване на точността (съответстващо на корен квадратен от увеличението на извадката).
Казус: определяне на размера на извадката за оценка на потенциала на пазара за продажби на столични недвижими имоти на купувачи от регионите
През ноември-декември 2016 г. проведохме проучване на търсенето на апартаменти в нови сгради в Москва и Санкт Петербург от жители на различни градове на Русия. Проучването включва три метода за събиране на данни: масово представително проучване на населението на възраст от 20 до 60 години (извършено с помощта на технологията CATI), както и серия от експертни интервюта с брокери и задълбочени интервюта с потенциални купувачи на апартаменти.
Проучването обхваща 33 града, характеризиращи се с повишено търсене на недвижими имоти в Санкт Петербург и Москва. Планираната извадка от изследването, изчислена по формули, възлиза на 21 500 респонденти. Този размер е значително по-голям от „стандартния“ размер на извадката, използван в маркетинговите проучвания. Каква е причината за толкова голям размер на извадката?
Работата е там, че клиентът се нуждаеше от оценки поотделно за всеки град, а не само „за цялата страна“. Всъщност ние не работим с 1 проба, а с 33 отделни проби за всеки град. Делът на хората, които се интересуват от покупка на апартамент в Санкт Петербург или Москва, е експертно определен на 5% от броя на жителите на изследваните градове.
В зависимост от важността на града за клиента, ръководителят на проекта от Агенцията определя допустимата статистическа грешка, в рамките на която трябва да се поберат крайните резултати. За това използвахме специален макрос в MS Excel, но тези изчисления могат да се извършат и с помощта на калкулатор за вземане на проби. В резултат на това размерът на извадката варира от 500 до 1000 респонденти за всеки от градовете в проучването, което дава общо 21 500 души.
- Определете структурата на целевата група. Планирате ли да анализирате отделни подгрупи или анализът на извадката като цяло ще бъде достатъчен?
- Определете желаната точност на данните. Например, ако трябва да оцените динамиката на пазарния дял за една година, включете приблизителната стойност на дела в специален калкулатор и „играйте“ с различни размери на извадката.
- Намерете баланс между разходите за събиране на данни (пряко пропорционални на размера на извадката) и необходимата точност.
Описание на калкулатора:
В полето „Размер на населението“трябва да въведете цяло неотрицателно число, равно на броя на обектите в популацията, от която се прави селекцията в извадката. Например, това може да бъде броят на документите в масива или, по-често, броят на населението, живеещо в определен район, или броят на хората в целевата група. На практика често възникват ситуации, когато извадковата съвкупност е 100 или повече пъти по-малка от генералната съвкупност. В този случай населението се счита за квазибезкрайно. Това параметърът е зададен по подразбиране(символ «∞» в полето„Размерът на населението» ).
След това трябва да изберете (чрез щракване с левия бутон на мишката, поставете точка в желания кръг) нивото на достоверност, на което ще бъде оценена грешката на извадката или нейния обем, тоест, като щракнете с левия бутон на мишката, поставете точка в желания кръг. Колкото по-високо е определеното ниво на увереност, толкова по-малък е шансът действителната грешка да надвиши теоретичната оценка или изчисленият размер на извадката да бъде недостатъчен, за да се направят оценки с точност, която не надвишава определената грешка. Ако е обозначена доверителната вероятностП , тогава вероятността че оценката на грешката или обема ще бъде неправилна равна на 1-R. ПриП =0,95 вероятност за грешкаравна на 0,05 (1 шанс на 20); приП =0,99, същата вероятност е 0,01 (1 шанс на 100).
Ако искате да изчислите грешката на извадката с определен размер, тогава в полето „Размер на извадката» трябва да се въведе неотрицателно число, равно на количествотообекти в извадката. След това щраквате с левия бутон върху бутона за изчисление, който трябва да светне в зелено, след като сте въвели коректно първоначалните данни. В полето « Теоретична статистическа грешка» ще се покаже число, по-голямо от 0 и по-малко от единица, в което вместо запетая се използва точка „. (с точност до 3 знака след десетичната запетая). Ако искате да преобразувате тази грешка в процент, просто умножете числото по 100 - мислено преместете десетичната запетая две позиции надясно. Така в дадения пример резултатите от изчислението показват, че теоретичната статистическа грешка на случайна вероятностна извадка от 1600 единици от квазибезкрайна популация с доверителна вероятност от 0,99 не надвишава 0,032 (3,2%).
В случай, че е необходимо да се изчисли размерът на извадковата популация от квазибезкрайна популация, достатъчна да осигури теоретична статистическа грешка не повече от посочената, трябва да попълните полето „Теоретична статистическа грешка“(число от 0 до 1, вместо десетичната запетая "," - десетична запетая«.» ; процентите трябва да се преобразуват в части от едно : 3,2%=0,032 и т.н.). Трябва също да зададете нивото на увереност, като щракнете с левия бутон върху точката в желания кръг вдясно от надписа „ Вероятност за доверие" След това просто трябва да щракнете с левия бутон върху зеления бутон "изчисление"и в полето" Размер на извадката"Ще видите резултата.
За въвеждане на нови данни и преизчисление натиснете черния бутон “ ясно» .
Статистическа популация- съвкупност от единици, които имат масов характер, типичност, качествена еднородност и наличие на вариация.
Статистическата популация се състои от материално съществуващи обекти (Служители, предприятия, държави, региони), е обект.
Единица от населението— всяка конкретна единица от статистическа съвкупност.
Една и съща статистическа съвкупност може да бъде хомогенна по една характеристика и разнородна по друга.
Качествена еднородност- сходство на всички единици от съвкупността по една основа и различие по всички останали.
В статистическата съвкупност разликите между една и друга единица на съвкупността често са от количествен характер. Количествените промени в стойностите на дадена характеристика на различни единици от съвкупността се наричат вариация.
Вариация на черта- количествена промяна в характеристика (за количествена характеристика) по време на прехода от една единица от съвкупността към друга.
Знак- това е свойство, характерна черта или друга характеристика на единици, обекти и явления, които могат да бъдат наблюдавани или измерени. Признаците се делят на количествени и качествени. Разнообразието и изменчивостта на стойността на даден признак в отделните единици на съвкупността се нарича вариация.
Атрибутивните (качествените) характеристики не могат да бъдат изразени числено (състав на населението по пол). Количествените характеристики имат числено изражение (състав на населението по възраст).
Индекс- това е обобщаваща количествена и качествена характеристика на всяко свойство на единици или агрегати като цяло при определени условия на време и място.
Карта за резултате набор от показатели, които цялостно отразяват изследваното явление.
Например, заплатата се изучава:- Знак - заплати
- Статистическа съвкупност - всички служители
- Единицата от съвкупността е всеки служител
- Качествена хомогенност - начислени заплати
- Вариация на знак - поредица от числа
Популация и извадка от нея
Базата е набор от данни, получени в резултат на измерване на една или повече характеристики. Наистина наблюдаван набор от обекти, статистически представен от редица наблюдения на случайна променлива, е вземане на проби, а хипотетично съществуващото (предполагаемо) - общо население. Популацията може да е ограничена (брой наблюдения N = конст) или безкрайно ( N = ∞), а извадка от популация винаги е резултат от ограничен брой наблюдения. Броят на наблюденията, образуващи извадка, се нарича размер на извадката. Ако размерът на извадката е достатъчно голям ( n → ∞) пробата се разглежда голям, иначе се нарича вземане на проби ограничен обем. Пробата се разглежда малък, ако при измерване на едномерна случайна променлива размерът на извадката не надвишава 30 ( н<= 30 ), и при измерване на няколко едновременно ( к) функции в многомерното релационно пространство нДа се кне надвишава 10 (н/к< 10) . Примерните форми вариационна серия, ако членовете му са редови статистики, т.е. примерни стойности на случайната променлива хсе подреждат във възходящ ред (класират), стойностите на характеристиката се извикват настроики.
Пример. Почти същият произволно избран набор от обекти - търговски банки на един административен район на Москва, може да се разглежда като извадка от генералната съвкупност на всички търговски банки в този район и като извадка от генералната съвкупност на всички търговски банки в Москва , както и по образец от търговските банки в страната и др.
Основни методи за организиране на вземане на проби
Надеждността на статистическите заключения и смислената интерпретация на резултатите зависи от представителностпроби, т.е. пълнота и адекватност на представянето на свойствата на генералната съвкупност, по отношение на които тази извадка може да се счита за представителна. Изследването на статистическите свойства на съвкупността може да се организира по два начина: с помощта непрекъснатоИ не непрекъснато. Непрекъснато наблюдениепредвижда преглед на всички единициизучавани съвкупност, А частично (избирателно) наблюдение- само части от него.
Има пет основни начина за организиране на пробно наблюдение:
1. прост произволен избор, при което обектите се избират на случаен принцип от съвкупност от обекти (например с помощта на таблица или генератор на произволни числа), като всяка от възможните извадки има еднаква вероятност. Такива проби се наричат всъщност произволно;
2. прост избор чрез редовна процедурасе извършва с помощта на механичен компонент (например дата, ден от седмицата, номер на апартамент, букви от азбуката и др.) и получените по този начин проби се наричат механичен;
3. стратифицираниподборът се състои в това, че общата съвкупност на обема се разделя на субпопулации или слоеве (страти) на обема, така че . Стратите са хомогенни обекти по отношение на статистически характеристики (например населението е разделено на страти по възрастови групи или социална класа; предприятията по отрасли). В този случай пробите се извикват стратифицирани(в противен случай, стратифициран, типичен, регионализиран);
4. методи сериенселекция се използват за формиране сериенили проби от гнезда. Те са удобни, ако е необходимо да се изследва едновременно „блок“ или поредица от обекти (например партида стоки, продукти от определена серия или населението на териториално-административното деление на страната). Изборът на серии може да се извърши чисто на случаен принцип или механично. В този случай се извършва пълна проверка на определена партида стока или цяла териториална единица (жилищна сграда или блок);
5. комбинирани(стъпковият) избор може да комбинира няколко метода за избор наведнъж (например стратифициран и случаен или случаен и механичен); такава проба се нарича комбинирани.
Видове селекция
от умразграничават се индивидуален, групов и комбиниран подбор. При индивидуален подборотделни единици от генералната съвкупност се избират в извадката, с групов избор- качествено хомогенни групи (серии) от единици и комбинирана селекциявключва комбинация от първия и втория тип.
от методсе отличава селекцията повтарящи се и неповтарящи сепроба.
Неповториминаречена селекция, при която единица, включена в извадката, не се връща към първоначалната популация и не участва в по-нататъшна селекция; докато броят на единиците в генералната съвкупност нсе намалява по време на процеса на подбор. При повтаря сеселекция уловенв извадката единица след регистрация се връща в генералната съвкупност и по този начин запазва равни възможности, заедно с други единици, да бъде използвана в последваща процедура за подбор; докато броят на единиците в генералната съвкупност ностава непроменена (методът рядко се използва в социално-икономическите изследвания). Въпреки това, с големи N (N → ∞)формули за повторяемселекцията се доближава до тези за повтаря сеселекция и последните практически се използват по-често ( N = конст).
Основни характеристики на параметрите на генералната и извадковата съвкупност
Статистическите заключения от изследването се основават на разпределението на случайната променлива и наблюдаваните стойности (x 1, x 2, ..., x n)се наричат реализации на случайната променлива х(n е размерът на извадката). Разпределението на случайна променлива в генералната съвкупност е от теоретичен, идеален характер и нейният извадков аналог е емпириченразпространение. Някои теоретични разпределения са специфицирани аналитично, т.е. техен настроикиопределя стойността на функцията на разпределение във всяка точка от пространството на възможните стойности на случайната променлива. Поради това за извадка функцията на разпределение е трудна и понякога невъзможна за определяне настроикисе оценяват от емпирични данни и след това се заместват в аналитичен израз, описващ теоретичното разпределение. В този случай предположението (или хипотеза) относно типа разпределение може да бъде или статистически правилно, или погрешно. Но във всеки случай емпиричното разпределение, реконструирано от извадката, само грубо характеризира истинското. Най-важните параметри на разпространение са очаквана стойности дисперсия.
По своята същност разпределенията са непрекъснатоИ отделен. Най-известното непрекъснато разпределение е нормално. Примерни аналози на параметрите и за него са: средна стойност и емпирична дисперсия. Сред дискретните в социално-икономическите изследвания най-често използваните алтернативен (дихотомичен)разпространение. Параметърът на математическото очакване на това разпределение изразява относителната стойност (или дял) единици от съвкупността, които имат изследваната характеристика (посочена е с буквата); делът на населението, което не притежава тази характеристика, се обозначава с буквата q (q = 1 - p). Дисперсията на алтернативното разпределение също има емпиричен аналог.
В зависимост от вида на разпределението и от метода на избор на съвкупност, характеристиките на параметрите на разпределението се изчисляват по различен начин. Основните за теоретични и емпирични разпределения са дадени в табл. 9.1.
Фракция на пробата k nСъотношението на броя на единиците в извадката от съвкупността към броя на единиците в генералната съвкупност се нарича:
kn = n/N.
Фракция на пробата wе съотношението на единиците, притежаващи изследваната характеристика хдо размера на извадката н:
w = n n /n.
Пример.В партида стоки, съдържаща 1000 единици, с 5% проба примерен дял k nпо абсолютна стойност е 50 единици. (n = N*0.05); ако в тази проба се открият 2 дефектни продукта, тогава процент дефекти на пробата wще бъде 0,04 (w = 2/50 = 0,04 или 4%).
Тъй като извадката от съвкупността е различна от общата съвкупност, има грешки при вземане на проби.
Таблица 9.1 Основни параметри на генералната и извадкова съвкупности
Грешки при вземане на проби
Във всеки случай (постоянен и избирателен) могат да възникнат грешки от два вида: регистрация и представителност. Грешки Регистрациямога да имам случаенИ систематиченхарактер. Случаенгрешките се състоят от много различни неконтролируеми причини, непреднамерени са и обикновено се балансират взаимно (например промени в производителността на устройството поради температурни колебания в помещението).
Систематиченгрешките са предубедени, защото нарушават правилата за избор на обекти за извадката (например отклонения в измерванията при промяна на настройките на измервателното устройство).
Пример.За оценка на социалното положение на населението в града се предвижда да бъдат анкетирани 25% от семействата. Ако изборът на всеки четвърти апартамент се основава на неговия брой, тогава съществува опасност от избор на всички апартаменти само от един тип (например едностайни апартаменти), което ще доведе до системна грешка и ще изкриви резултатите; изборът на номер на апартамент по партида е по-предпочитан, тъй като грешката ще бъде случайна.
Грешки в представителносттаса присъщи само на извадковото наблюдение, те не могат да бъдат избегнати и възникват в резултат на това, че извадковата съвкупност не възпроизвежда напълно генералната съвкупност. Стойностите на показателите, получени от извадката, се различават от показателите със същите стойности в общата съвкупност (или получени чрез непрекъснато наблюдение).
Пристрастност при вземане на пробие разликата между стойността на параметъра в популацията и нейната извадкова стойност. За средната стойност на количествена характеристика тя е равна на: , а за дела (алтернативна характеристика) - .
Грешките при извадката са присъщи само на извадковите наблюдения. Колкото по-големи са тези грешки, толкова повече емпиричното разпределение се различава от теоретичното. Параметрите на емпиричното разпределение са случайни променливи, следователно грешките на извадката също са случайни променливи, те могат да приемат различни стойности за различни проби и затова е обичайно да се изчислява средна грешка.
Средна извадкова грешкае величина, изразяваща стандартното отклонение на средната стойност на извадката от математическото очакване. Тази стойност, подчинена на принципа на случаен подбор, зависи основно от размера на извадката и от степента на вариация на характеристиката: колкото по-голяма е и колкото по-малка е вариацията на характеристиката (и следователно стойността), толкова по-малка е средната грешка на извадката . Връзката между дисперсиите на генералната и извадковата съвкупности се изразява с формулата:
тези. когато е достатъчно голям, можем да приемем, че . Средната извадкова грешка показва възможните отклонения на параметъра на извадката от съвкупността от параметъра на генералната съвкупност. В табл Таблица 9.2 показва изрази за изчисляване на средната грешка на извадката за различни методи за организиране на наблюдението.
Таблица 9.2 Средна грешка (m) на средната стойност на пробата и съотношението за различни типове проби
Къде е средната стойност на вариациите на извадката в рамките на групата за непрекъснат атрибут;
Средна стойност на вътрешногруповите дисперсии на пропорцията;
— брой избрани серии, — общ брой серии;
 ,
,
където е средната стойност на th-та серия;
— общата средна стойност за цялата извадкова популация за непрекъсната характеристика;
 ,
,
където е делът на характеристиката в тата серия;
— общия дял на характеристиката в цялата съвкупност от извадки.
Големината на средната грешка обаче може да се прецени само с определена вероятност P (P ≤ 1). Ляпунов А.М. доказа, че разпределението на извадковите средни стойности и следователно техните отклонения от общата средна стойност за достатъчно голям брой приблизително се подчинява на нормалния закон за разпределение, при условие че генералната съвкупност има крайна средна и ограничена дисперсия.
Математически това твърдение за средната стойност се изразява като:

а за дяла изразът (1) ще приеме формата:
Където  -
Има пределна извадкова грешка, което е кратно на средната извадкова грешка ,
а коефициентът на множественост е тестът на Стюдънт ("коефициент на увереност"), предложен от W.S. Госет (псевдоним "Студент"); стойностите за различни размери на извадката се съхраняват в специална таблица.
-
Има пределна извадкова грешка, което е кратно на средната извадкова грешка ,
а коефициентът на множественост е тестът на Стюдънт ("коефициент на увереност"), предложен от W.S. Госет (псевдоним "Студент"); стойностите за различни размери на извадката се съхраняват в специална таблица.

Следователно израз (3) може да се чете по следния начин: с вероятност P = 0,683 (68,3%)може да се твърди, че разликата между извадката и общата средна стойност няма да надвишава една стойност на средната грешка m(t=1), с вероятност P = 0,954 (95,4%)- че няма да надвишава стойността на две средни грешки m (t = 2),с вероятност P = 0,997 (99,7%)- няма да надвишава три стойности m (t = 3) .По този начин вероятността тази разлика да надхвърли три пъти средната грешка се определя от ниво на грешкаи не възлиза на повече 0,3% .
В табл 9.3 показва формули за изчисляване на максималната грешка на извадката.
Таблица 9.3 Гранична грешка (D) на извадката за средната стойност и съотношението (p) за различни видове наблюдение на извадката
Обобщаване на резултатите от извадката към популацията
Крайната цел на извадковото наблюдение е да се характеризира генералната съвкупност. При малки размери на извадката емпиричните оценки на параметрите ( и ) могат да се отклоняват значително от техните истински стойности ( и ). Следователно е необходимо да се установят граници, в които се намират истинските стойности ( и ) за примерните стойности на параметрите ( и ).
Доверителен интервална всеки параметър θ от генералната съвкупност е произволният диапазон от стойности на този параметър, който с вероятност близка до 1 ( надеждност) съдържа истинската стойност на този параметър.
Пределна грешкапроби Δ ви позволява да определите граничните стойности на характеристиките на общата популация и техните доверителни интервали, които са равни:
Долен ред доверителен интервалполучено чрез изваждане максимална грешкаот средната извадка (дял), а горната като я добавим.
Доверителен интервалза средната използва максималната грешка на извадката и за дадено ниво на достоверност се определя по формулата:
Това означава, че с дадена вероятност Р, което се нарича ниво на достоверност и се определя еднозначно от стойността T, може да се твърди, че истинската стойност на средната стойност е в диапазона от ![]() , а истинската стойност на дела е в диапазона от
, а истинската стойност на дела е в диапазона от
При изчисляване на доверителния интервал за три стандартни нива на доверителност P = 95%, P = 99% и P = 99,9%стойността се избира от . Приложения в зависимост от броя на степените на свобода. Ако размерът на извадката е достатъчно голям, тогава стойностите, съответстващи на тези вероятности Tса равни: 1,96, 2,58 И 3,29 . По този начин пределната грешка на извадката ни позволява да определим граничните стойности на характеристиките на популацията и техните доверителни интервали:
Разпределението на резултатите от извадковото наблюдение на общата съвкупност в социално-икономическите изследвания има свои собствени характеристики, тъй като изисква пълно представяне на всичките му видове и групи. Основата за възможността за такова разпределение е изчислението относителна грешка:

Където Δ % - относителна максимална извадкова грешка; , .
Има два основни метода за разширяване на извадковото наблюдение към популация: пряко преизчисляване и коефициентен метод.
Същност директно преобразуванесе състои от умножаване на средната стойност на извадката!!\overline(x) по размера на популацията.
Пример. Нека средният брой малки деца в града се изчисли по извадковия метод и възлиза на един човек. Ако в града има 1000 млади семейства, то необходимите места в общинските детски ясли се получават, като тази средна стойност се умножи по размера на генералната съвкупност N = 1000, т.е. ще разполага с 1200 места.
Метод на коефициентитеПрепоръчително е да се използва в случай, когато се извършва селективно наблюдение, за да се изяснят данните от непрекъснатото наблюдение.
Използва се следната формула:
където всички променливи са размерът на популацията:
Необходим размер на извадката
Таблица 9.4 Необходим размер на извадката (n) за различни видове организация за наблюдение на извадката
При планиране на извадково наблюдение с предварително определена стойност на допустимата извадкова грешка е необходимо правилно да се оцени изискваната размер на извадката. Този обем може да се определи на базата на допустимата грешка по време на наблюдение на извадката въз основа на дадена вероятност, която гарантира допустимата стойност на нивото на грешка (като се вземе предвид методът на организиране на наблюдението). Формулите за определяне на необходимия размер на извадката n могат лесно да бъдат получени директно от формулите за максимална грешка на извадката. И така, от израза за пределната грешка:
размерът на извадката се определя директно н:
Тази формула показва, че с максималната грешка на извадката намалява Δ необходимият размер на извадката нараства значително, което е пропорционално на дисперсията и квадрата на t теста на Стюдънт.
За конкретен метод за организиране на наблюдение необходимият размер на извадката се изчислява по формулите, дадени в табл. 9.4.
Примери за практически изчисления
Пример 1. Изчисляване на средна стойност и доверителен интервал за непрекъсната количествена характеристика.
За оценка на скоростта на разплащане с кредиторите в банката е извършена произволна извадка от 10 платежни документа. Техните стойности се оказаха равни (в дни): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Необходимо с вероятност Р = 0,954определяне на пределната грешка Δ примерна средна стойност и доверителни граници на средното време за изчисление.
Решение.Средната стойност се изчислява по формулата от табл. 9.1 за извадката
![]()
Дисперсията се изчислява по формулата от табл. 9.1.
![]()
Средна квадратна грешка за деня.
Средната грешка се изчислява по формулата:
![]()
тези. средното е x ± m = 12,0 ± 2,3 дни.
Надеждността на средната стойност беше
![]()
Изчисляваме максималната грешка по формулата от табл. 9.3 за повторно вземане на проби, тъй като размерът на популацията е неизвестен, и за Р = 0,954ниво на увереност.
Така средната стойност е `x ± D = `x ± 2m = 12,0 ± 4,6, т.е. истинската му стойност е в диапазона от 7,4 до 16,6 дни.
Използване на t-таблица на Стюдънт. Приложението ни позволява да заключим, че за n = 10 - 1 = 9 степени на свобода, получената стойност е надеждна с ниво на значимост от £ 0,001, т.е. получената средна стойност е значително различна от 0.
Пример 2. Оценка на вероятността (генерален дял) Стр.
Механичен извадков метод за изследване на социалния статус на 1000 семейства разкрива, че делът на семействата с ниски доходи е w = 0,3 (30%)(пробата беше 2% , т.е. n/N = 0,02). Изисква се с ниво на увереност р = 0,997определяне на индикатора Рсемейства с ниски доходи в целия регион.
Решение.Въз основа на представените стойности на функцията Ф(t)намерете за дадено ниво на доверие Р = 0,997значение t = 3(виж формула 3). Пределна грешка на дроб wопределете по формулата от таблицата. 9.3 за неповтарящо се вземане на проби (механичното вземане на проби винаги е неповтарящо се):
Максимална относителна грешка на извадката в % ще бъде:
Вероятността (общият дял) на семействата с ниски доходи в региона ще бъде р=w±Δw, а доверителните граници p се изчисляват въз основа на двойното неравенство:
w — Δ w ≤ p ≤ w — Δ w, т.е. истинската стойност на p е в рамките на:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Така с вероятност от 0,997 може да се твърди, че делът на семействата с ниски доходи сред всички семейства в региона варира от 28,6% до 31,4%.
Пример 3.Изчисляване на средната стойност и доверителния интервал за дискретна характеристика, определена от интервална серия.
В табл 9.5. уточнява се разпределението на приложенията за производство на поръчки според времето на тяхното изпълнение от предприятието.
Таблица 9.5 Разпределение на наблюденията по време на появаРешение. Средното време за изпълнение на поръчките се изчислява по формулата:
Средният период ще бъде:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 месеца.
Получаваме същия отговор, ако използваме данните за p i от предпоследната колона на таблицата. 9.5, използвайки формулата:
Имайте предвид, че средата на интервала за последната градация се намира чрез изкуственото й допълване с ширината на интервала на предишната градация, равна на 60 - 36 = 24 месеца.
Дисперсията се изчислява по формулата
![]()
Където x i- средата на интервалната серия.
Следователно!!\sigma = \frac (20^2 + 14^2 + 1 + 25^2 + 49^2)(4), а средната квадратична грешка е .
Средната грешка се изчислява по месечната формула, т.е. средната стойност е!!\overline(x) ± m = 23,1 ± 13,4.
Изчисляваме максималната грешка по формулата от табл. 9.3 за повторна селекция, тъй като размерът на популацията е неизвестен, за ниво на достоверност 0,954:
Така че средната стойност е:
тези. истинската му стойност е в диапазона от 0 до 50 месеца.
Пример 4.За да се определи скоростта на разплащане с кредиторите на N = 500 корпоративни предприятия в търговска банка, е необходимо да се проведе извадково изследване, като се използва метод на случаен неповтарящ се подбор. Определете необходимия размер на извадката n, така че с вероятност P = 0,954 грешката на средната стойност на извадката да не надвишава 3 дни, ако оценките на опита показват, че стандартното отклонение s е 10 дни.
Решение. За да определим броя на необходимите изследвания n, ще използваме формулата за неповтарящ се подбор от таблицата. 9.4:

В него стойността t се определя от ниво на достоверност P = 0,954. Тя е равна на 2. Средната квадратична стойност е s = 10, размерът на популацията е N = 500, а максималната грешка на средната стойност е Δ x = 3. Замествайки тези стойности във формулата, получаваме:
![]()
тези. Достатъчно е да съставите извадка от 41 предприятия, за да оцените необходимия параметър - скоростта на разплащанията с кредиторите.



